cat articles/ai-predictions-graded-matchday-1.mdx
Comunio World Cup 2026 · Part 2Predictions, graded honestly: good at calling who'll play, weak at calling the score
After one World Cup matchday, I graded my AI agents' predictions against reality in public — reliable at calling who'll play, weak at calling the score, and the grader itself had bugs I had to fix first.
Jun 22, 2026 · by Daniel Deusing · ~23 min read #ai #agents #football
In the first article I wrote about a team of AI agents I built to play a 2026 World Cup fantasy league, and I made a promise: I’d come back once the matches were played and grade the predictions in public — properly, with the misses on show, not just the wins. The first round of group games is done. Here’s the scorecard.
The squad itself is doing fine — it sits near the top of our little league of friends after one round. But I want to be honest about why: that’s mostly the buying-and-selling from part one, not the match predictions. The predictions are a different, more interesting story — and the headline is a split I didn’t expect:
The flashy part — calling scores — is, for now, the part it’s least good at. The unglamorous part — calling who’ll actually be in the starting eleven — is where it’s already reliable. The honest reason for the gap isn’t that one reads data and the other guesses — both lean on data (team news and line-up leaks for the eleven; betting markets and form for the scores) and both involve real guesswork. The difference is how much of the answer is settled before kickoff. Who starts is mostly decided in advance, so good information carries you a long way — bar the occasional coach’s surprise that can’t be read from the outside. A scoreline is mostly decided across ninety minutes of chaos, so even the best information only narrows it; it can’t pin it down. Same system, two problems with very different amounts of luck baked in — and that distinction, not the football, is the useful part.
But before any of the grades, a confession about the grading itself — because that’s where the first real lesson is.
Quick recap, in case you missed part one: I’m in a fantasy game where you buy and sell real footballers in a blind auction — sealed bids, nobody sees anyone else’s, highest number wins — and a team of AI agents does the daily homework. This article is about the other promise I made there: that the system would grade its own predictions against reality, in public, from the night the first whistle blew.
I had to fix the grader before I could trust it
Here’s the part that’s easy to skip. When the first results came in, my shiny new accuracy page produced numbers I couldn’t trust — not because the predictions were good or bad, but because the grading had bugs. Three of them are worth naming, because each is a mistake any company makes the first time it tries to measure an AI system honestly.
It graded stale predictions. One of my players, the Austrian midfielder Laimer, sat in the evaluation marked “won’t play” at 95% — and then he played the full ninety minutes. The system looked badly wrong. But it wasn’t wrong this week: that 95% was a three-week-old guess that never got refreshed before the match. I was grading a forecast the system had effectively forgotten it made. Garbage in, garbage grade.
It couldn’t tell two people apart. Three players — including an England defender named O’Reilly — were marked “didn’t play” when they had, in fact, started the whole match. The reason is dull and important: the player in the live line-up data and the player in my prediction were the same human, recorded under two slightly different names, and the system treated them as strangers. That’s a textbook entity-resolution failure.
It gave a home advantage at a tournament with no home games. The model quietly handed the team listed first a home-pitch edge — but World Cup group games are played on neutral grounds (bar the hosts). A small assumption, baked in from ordinary league football, quietly skewing everything.
Notice what these have in common: none of them were the AI being “dumb.” The agents did roughly what they were told. The failures were in the measurement — the plumbing that decides what counts as right. And that’s the lesson I’d underline for anyone betting real budget on an AI project: building the thing is the easy half. Building a yardstick you can actually trust is the hard half, and it’s the half that gets skipped. A number you can’t defend is worse than no number, because it makes you confident and wrong at the same time.
The fixes were mostly boring, which is the point. A staleness guard — a plain bit of code, no AI, that throws out any forecast not refreshed for the matchday it’s grading — now runs every cycle, and a fresh set of predictions is locked in on the morning of each game (no more 21-day-old ghosts). A growing alias map — a lookup table of name equivalents — teaches the system that “Nico O’Reilly” and “O’Reilly” are one man. The neutral-ground rule is now written down. Line-ups are checked against the relevant Wikipedia match article — server-rendered, fast, with the confirmed eleven and the substitutes a couple of hours after the final whistle, every outlier citing its source. And results now get an honest four-colour code, which you’ll see below. The principle underneath all of it: use the expensive, clever tool (the AI) only where judgement is genuinely needed, and wrap it in cheap, boring, unbreakable code everywhere a guarantee matters.
The good news: who’ll play is mostly knowable — and we read it well
Now the grades. Start with what worked, because it surprised me how well it worked.
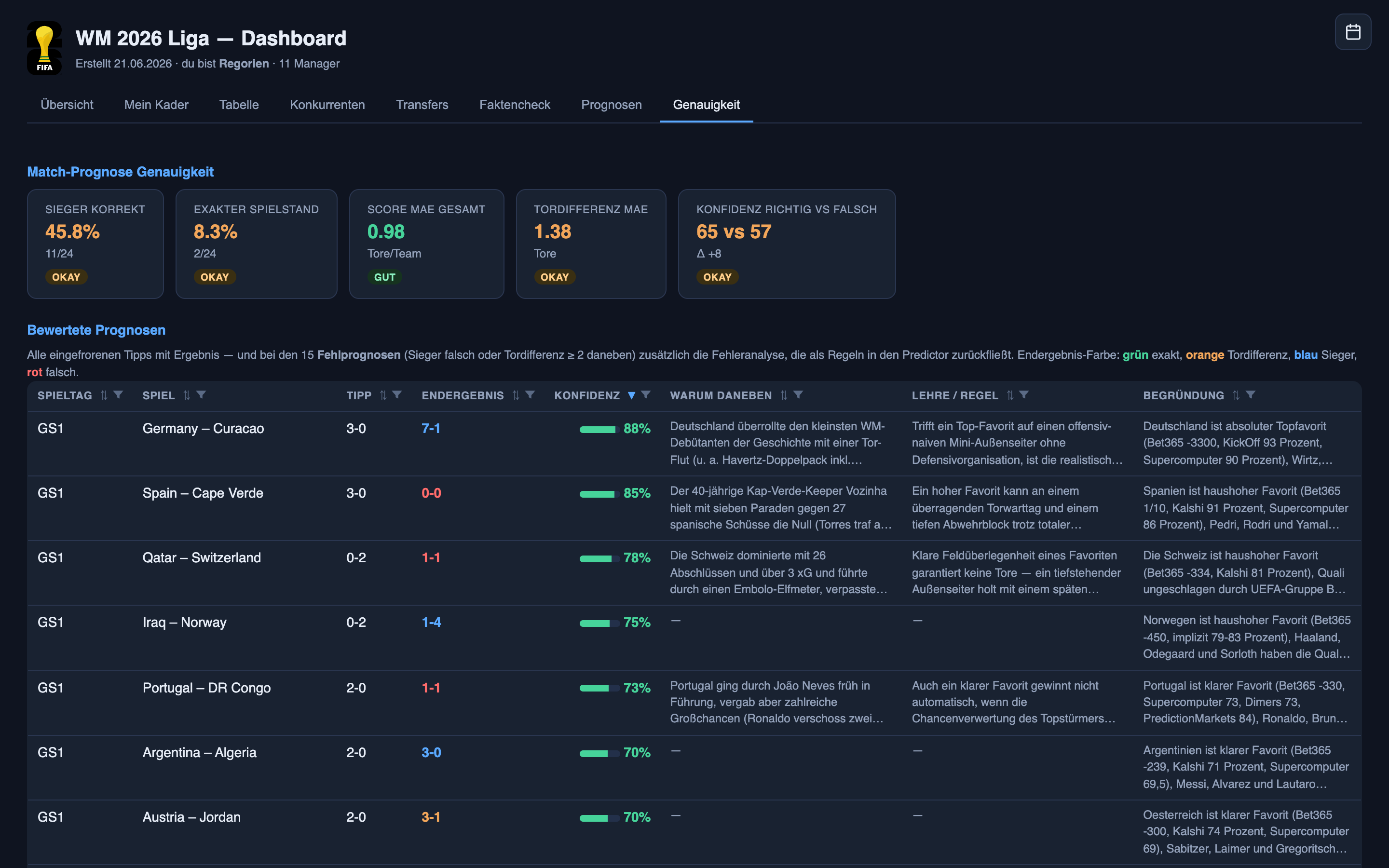
Every day, for every player, the system produces a number it calls p_start. Then the match happens, and we check.
The right way to judge a confidence score isn’t “was it right.” It’s calibration.
Against that bar, the system did well. Over 172 starting-eleven calls in the opening round (the stale ones thrown out), it was right 84% of the time — but the shape matters more than the headline:
- When it said a player had a 0–20% chance of starting (71 calls), they started about 13% of the time. Just about right on the long shots.
- When it said 80–100% (44 calls), they started 91% of the time. When this system is confident, you can believe it.
- The soft spot was the muddy middle. In the 20–40% band (just 24 calls) it implied roughly a one-in-three chance, but those players started only about one in eight times — overconfident, clearly.

A fair caveat: this is one round, and some bands hold only a couple of dozen calls, so read it as a signal to watch, not a verdict carved in stone. But why is this the steadier half? Because who starts is largely knowable in advance: team news, a press conference, a coach’s habits, an injury report. Most of the work is disciplined reading — gathering what’s already public, faster and more consistently than I would by hand — and only a slice is genuine guesswork: the rotation calls, the coach who springs a surprise no team-sheet reading could catch. That mix is exactly what the calibration shows: the reading is why the confident bands land, the guessing is why the middle band wobbles.
What it got right and wrong about my own players
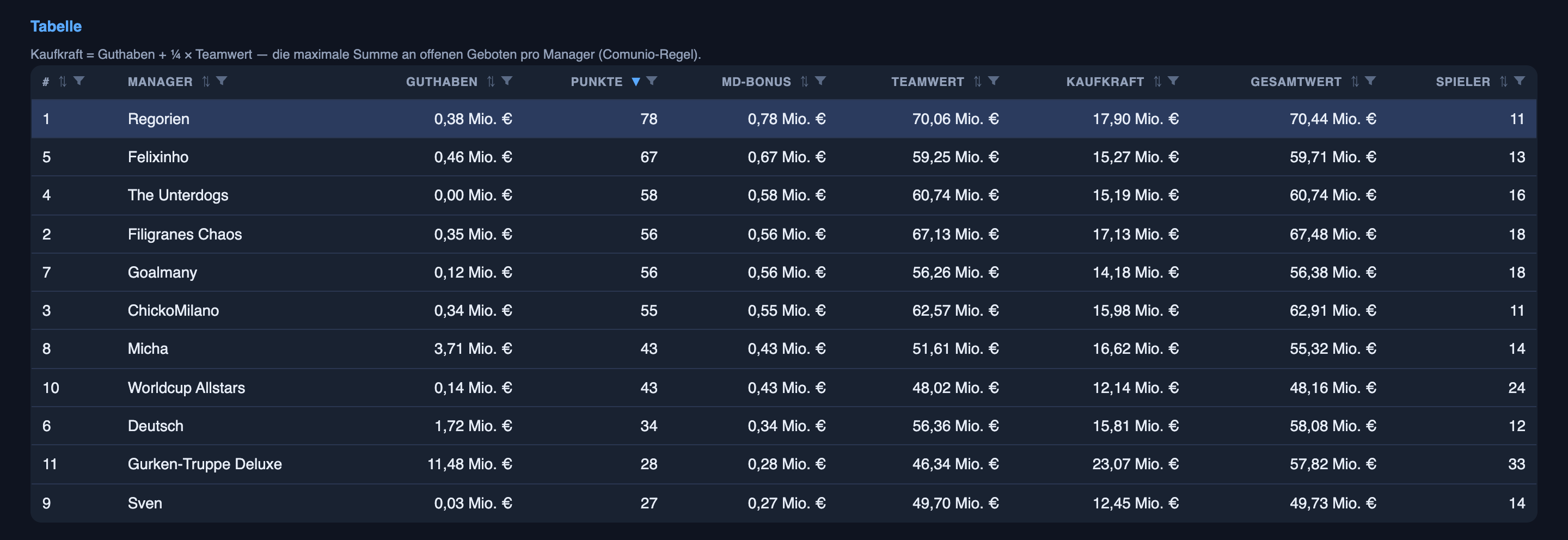
Abstract calibration is one thing. Here’s what it actually meant for players I owned, won with, and lost on — the honest ledger. Every call lives on the same daily screen: each player with a start probability, a play probability, a hold-or-sell verdict, and a note that links its sources.
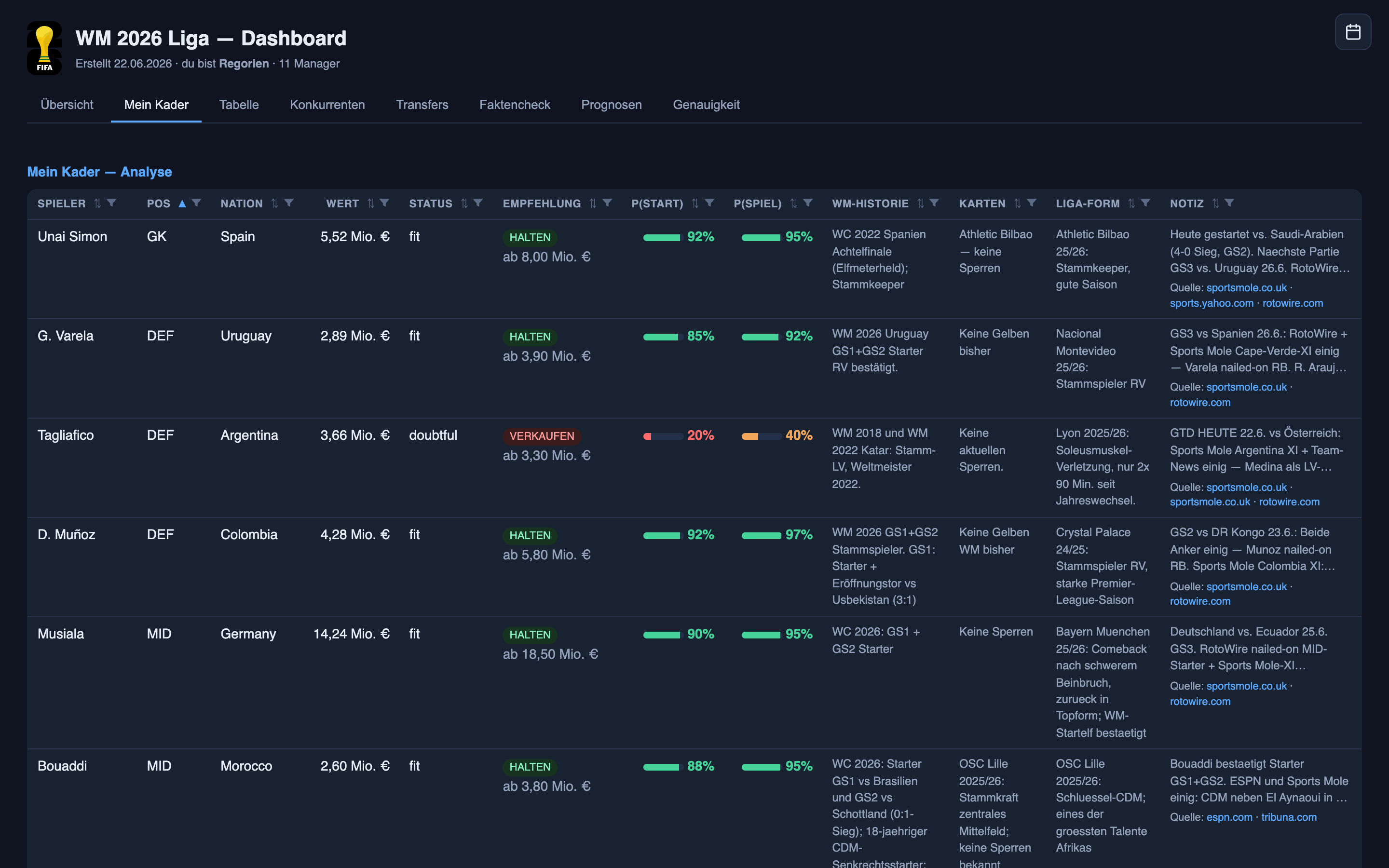
The hard one it got right: Unai Simón. Spain’s goalkeeper had a rough run-in, the press was full of rotation talk, and the coach gave no clear word either way — a genuinely murky call, not a gimme. The system stayed on the side of him starting and held that line through the noise. He started and played all ninety. That’s the system doing what I most want from it: the outside picture said “maybe,” the system said “he starts,” and it was right. A read of a murky situation, not a fact copied off a team sheet — and it’s the kind the who-plays side gets right more often than not.
The miss that cost me: Crepeau. I sold Canada’s keeper because the system had him at only 40% to start — a lean towards the bench. He started all ninety and scored four points I no longer had. A real loss, and one I can lay at the model’s feet: 40% wasn’t “no,” it was a coin-flip dressed as a lean, and I treated it as a decision.
The other side of the same coin: Asare. I bought Ghana’s keeper because the system put him at 55% — a lean towards starting. He didn’t start; he only came on when Ghana’s first-choice keeper, Ati Zigi, went off injured. Two transfers, opposite directions, same root cause: in the 40–60% band, the system’s confidence is barely better than a toss, and I keep mistaking “barely” for “probably.”
The confident one that still missed: Angulo. The Ecuador forward — a hero of part one — was at 78% to start. He didn’t; he came off the bench in the 56th minute. That’s a call in the 60–80% band, the one the calibration chart shows running about eight points hot. So the anecdote and the data agree: when this system says “quite likely,” shave a bit off.
And then the curveballs no model could have read: a backup Australian keeper we had at 2% started the full ninety because the coach benched his first choice the morning of the game; a Colombian midfielder at 3% played eighty minutes. Pure coaching whim, decided in a dressing room, unknowable from the outside. Those are the irreducible misses — and the honest thing is to count them, not explain them away.
The deeper trap: predicting who plays is not predicting how they’ll do
Here’s the one that taught me the most. Valery, a Tunisia defender, started and played 72 minutes — the system had him likely to feature, and the line-up read was right. The problem is that Tunisia were taken apart 5–1, and a defender on the wrong end of that came away with −2 points. I picked a player the system correctly said would play, and lost points anyway.
That gap matters everywhere. “Will this person be on shift” and “will this shift go well” are different questions, and a system that’s good at the first can be useless at the second if you confuse them. The fix isn’t a better line-up model — it’s adding the second question explicitly: given who’s playing and who they’re playing against, what’s the expected outcome, and how badly can it go? A starter on a team about to be overrun is a trap the line-up forecast can’t see by itself.
The bad news: calling the score is the weak half — and partly always will be
Which brings us to the scorelines, where the system was, plainly, not good.
Across all 24 opening matches it got the winner right 46% of the time — wrong more than half the time — and the exact score right just 8% (two matches out of 24). A blind guess across win, draw and lose lands near a third, so the model isn’t picking at random; it’s just not calling them well.
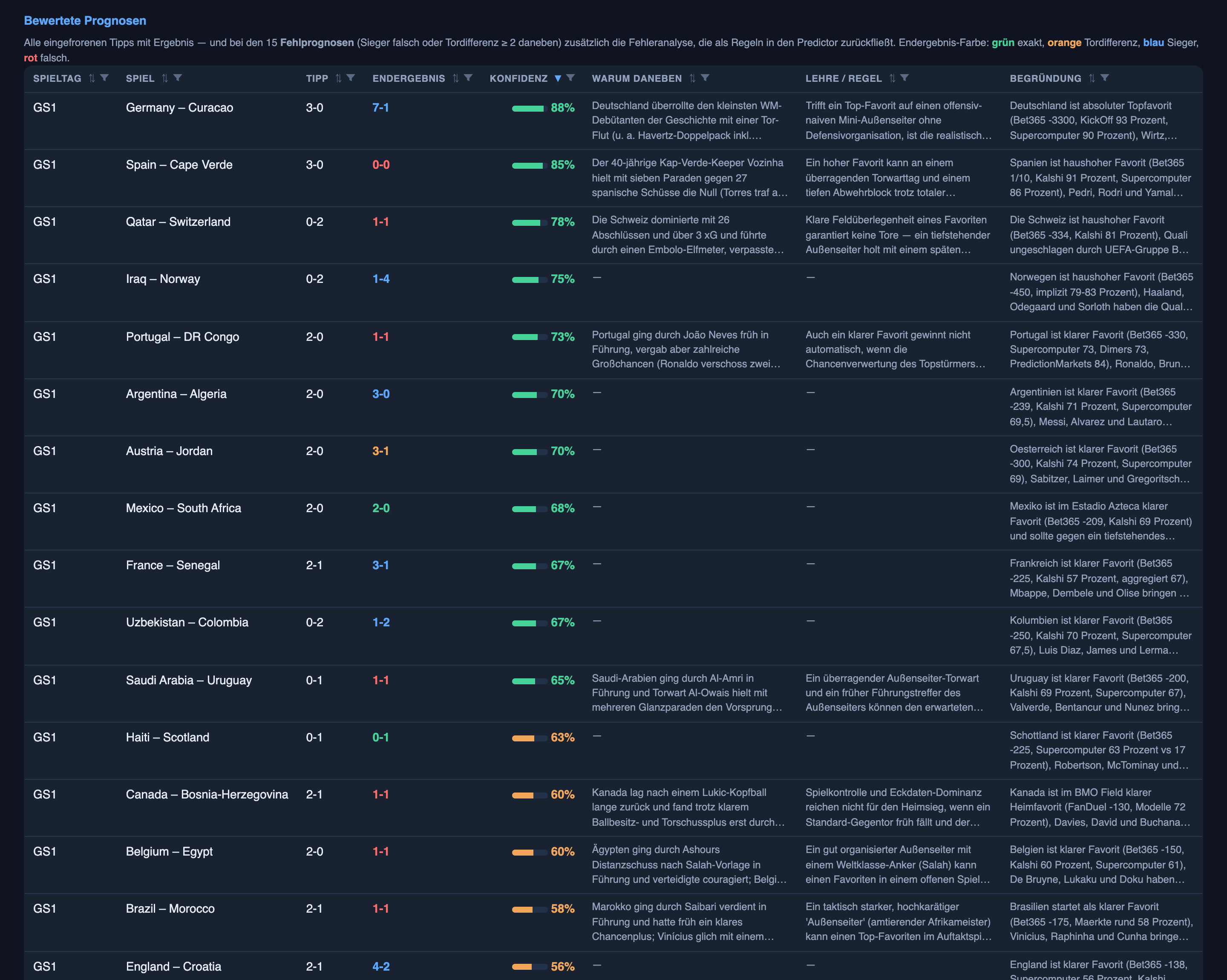
Three matches tell the whole story.
Spain 0–0 Cape Verde — the genuinely unforeseeable one. The system tipped Spain to win 3–0 at 85% confidence. Spain are a giant; Cape Verde were World Cup debutants; the betting markets agreed; everything pointed one way. It finished 0–0. There’s no lesson here except humility: sometimes a heavy favourite runs into a packed defence and a goalkeeper having the afternoon of his life, and no amount of intelligence foresees a specific 0–0. The honest fix isn’t “predict it better” — it’s “don’t be 85% sure of anything in a single low-scoring game.”
Turkey 0–2 to Australia — the one we arguably should have leaned differently on. Here the system actually favoured Turkey, tipping them to win 2–1 at 55%. They lost 0–2 and looked poor. Could we have known? Partly — a team’s recent form and squad depth are readable, and 55% was already a near-coin-flip, so the model wasn’t confident so much as mildly wrong. This is the middle ground: not unforeseeable like Spain, not a systematic bug — just a lean that should probably have gone the other way.
Tunisia 1–5 to Sweden — the rout we under-counted. The system tipped a narrow Sweden win, 1–0. Sweden won 5–1. It got the winner right and the scale completely wrong — and that same blind spot is why Valery’s minus points blindsided me. This is the opposite error to Spain: there, we were too bold on a favourite who drew; here, too timid on a mismatch that became a massacre.
Put together, those three are the real diagnosis. The system isn’t simply “too confident” or “too cautious” — it’s wrong about how football scores behave. Goals are rare, a whole match can swing on one, and rare events are dominated by luck no model can remove because it hasn’t happened yet. There’s real signal to lean on — the betting markets, the form guide, the better team winning more often than not, and the system uses all of it — but it stays buried under that randomness. The single most important thing to understand about prediction, in football or in business: some questions have answers waiting to be found, and some are genuinely up to chance. A good system has to know which is which — loud where there’s signal, humble where there’s only noise. This week, mine wasn’t humble enough: its confidence barely separated its hits from its misses (about 65% sure when right, 57% when wrong). Closing that gap matters more than chasing a couple of correct scorelines — and it’s one of the first things I’ve changed for matchday two.
How the predictions are made — and how the system actually learns
It’s worth pulling the curtain back, because the “how it learns” part is where this stops being about football.
Before each matchday, a researcher agent goes nation by nation and assembles the picture — likely line-ups, injuries, form, who’s rotating. A predictor agent turns that into a scoreline and a confidence. None of it is hard-coded rules I wrote months ago; the agents read the current world each time and reason fresh. That’s the difference between automating a report and hiring an analyst who happens to be made of software.
But reasoning fresh isn’t the same as learning. So this week I added a new piece: an evaluator agent — picture a quality-control inspector who comes in after the shift, sees what the line got wrong, and writes up the patterns. After the matches, it pulls the real results and line-ups, scores both, and — the key step — distils the misses into a short list of plain-language lessons. Not a data dump; a handful of patterns, de-duplicated, each with evidence and a concrete rule change. Some of the lessons it wrote itself this week:
“Favourites against deep-lying underdogs with a strong goalkeeper were systematically overrated — territorial dominance didn’t turn into goals; the underdog grabbed a draw from a late set piece.” Evidence: Spain–Cape Verde, Qatar–Switzerland, Belgium–Egypt.
“Blow-outs against offensively naïve minnows were underrated, because low confidence was wrongly equated with few goals. Decouple confidence from scoreline.” Evidence: Germany, tipped 3–0, won 7–1; Sweden 1–0 → 5–1.
“World Cup group games are on NEUTRAL ground — there is no home advantage except the hosts. The team listed first was wrongly given a home edge.”
That’s the loop closing. Before the next matchday, the predictor reads its lessons file and the researcher reads its own, and both adjust. The line-up side even wrote itself this note — “the 20–40% band runs hot; the 80–100% band is well-calibrated, trust it” — the system diagnosing its own weak spot, in writing, for next time.
Now the honest boundary, because this is where hype usually takes over. When I say the system “learns,” I do not mean it rewires some giant brain overnight. There are two ways an AI can change. One is expensive and slow — retraining the model itself, a black box at the end. The other is what I’m doing: the lessons sit in a plain text file the model reads at the start of each run, like a sharp new hire who keeps a notebook of “things I got wrong and what I’ll do differently” and reviews it before each task. It’s cheap, it’s instant, and — the part that matters for a business — it’s inspectable: I can read every lesson, argue with it, delete a bad one. And bad ones happen — an evaluator can write a plausible-sounding lesson that’s actually wrong, which is exactly why a human reads them before they feed the next round. A system whose learning you can read and overrule is one you can run inside a company. A black box that “just gets better” is one you’ll never get past your auditor.
And there’s a ceiling. The loop can fix biases — the phantom home advantage, the reflexive 1–1, the overconfident middle band. Those are real, systematic, correctable, and I expect them to shrink next round. What it can’t fix is the randomness — the irreducible luck in a low-scoring game. No notebook makes a 0–0 upset foreseeable. So the smart goal isn’t “predict scores better.” It’s “know which calls deserve confidence and which are honestly coin-flips” — and there, the loop genuinely helps.
Strip the football out
Read the last few sections again, but delete the word “football.”
A system makes forecasts. You score them honestly — and the first thing you find is that your scoring itself was unreliable: grading stale inputs, confusing two records of the same entity, carrying a hidden assumption from the wrong context. So you fix the scorer with cheap, rule-based checks before you trust a single number. Then your forecasts split cleanly in two: the ones about knowable things are sharp, and the ones about genuinely uncertain things are mediocre — and the real win is a system honest enough to tell you which is which. And you learn not by retraining a black box but by keeping a readable notebook of lessons a human can audit.
Make it concrete. If someone offered to predict your exact revenue next quarter to the euro, you’d be right to be sceptical — that’s a Spain-versus-Cape-Verde problem, mostly noise. But “which of our customers are quietly drifting toward leaving,” “which supplier’s prices have crept up faster than the market,” “which invoice this week doesn’t look like the others” — those are who-will-start problems: the answer is already in your own data, something just has to read it every morning, score itself honestly, and tell you how sure it is. And — the Valery lesson — don’t stop at “who’ll be on shift”; ask “and how is that shift likely to go,” because the two are different questions. That’s demand forecasting, churn detection, supplier-risk monitoring, anomaly detection — and the same shape of system runs just as well pointed at your own data behind your own firewall, not the open web. The footballers just make the scoreboard public and the stakes low enough to show the whole thing, misses and all.
Okay. Back to the game.
What I changed for matchday two — and what I expect
Almost everything useful this week came from the misses, not the wins. The lessons didn’t just get written down; they fed back into two concrete sets of changes before the next round kicked off — one for the line-up calls, one for the scores. On the record, here’s what’s actually different, and what I expect from each.
The line-up calls (who’ll play) — mostly fixing calibration and blind spots:
- Pull down the overconfident middle. The 20–40% band ran about 18 points hot, so it gets cut; the 40–60% and 60–80% bands were roughly 8 points high, so they get trimmed. The 80–100% band is left alone — it was already honest.
- Stop treating only the famous names as locked. The opening round was full of unglamorous regulars from smaller nations we’d parked at 2–15% who started anyway — so the researcher now credits an established starter regardless of profile, and treats a big name who’s lost his place with more suspicion (fame isn’t the current pecking order).
- Flag the opener curveball. A coach resting a fit first-choice — the call that cost me with that backup keeper — is now a known risk, not a surprise.
- Keep the inputs fresh. The staleness guard plus a full refresh on the morning of each game means no more three-week-old ghosts in the grade.
What I expect: the calibration tightens, especially that middle band. The headline 84% may not jump — but it gets more honest, which is the point.
The score calls — here the lessons are about how goals actually behave:
- Decouple confidence from scoreline. Low confidence stopped meaning “few goals,” so a genuine mismatch can be tipped as the rout it is, not a polite 3–0 (Germany 7–1, Sweden 5–1 are what that miss looked like).
- Hedge the heavy favourite. Against a deep-defending underdog with a good keeper, expect the draw far more often — and stop being 85% sure of a 3–0 (Spain 0–0; the cluster of 1–1s).
- Break the reflexive 1–1. In a coin-flip where one side dominates the ball, lean to a narrow win for that side instead of splitting the difference.
- No home advantage at a neutral tournament (bar the hosts).
- Widen the confidence where it’s a toss-up. Say “this one’s a coin-flip” out loud instead of faking precision — that 65-vs-57 gap is the one to close.
What I expect: winner-accuracy should climb off 46%. I’m still not promising good scorelines — the randomness is real — but the confidence should at least start telling the truth about itself.
The third change is the quiet one: the grading itself is now dated, colour-coded, self-correcting and public, so none of the above can flatter me in the dark.
Which sets up the honest test. After matchday two I’ll publish this same scorecard again — and you’ll see, in public, whether these changes actually moved the numbers or just sounded good on paper. That, in the end, is the only way to tell a system that learns from one that merely reports. The whole thing stays in the open, scored against reality, updated after every round — you can watch it get better, or fail to, without taking my word for any of it.
A last thought, then I’ll let you go. The most useful thing this week didn’t come from the AI being clever. It came from being forced to answer two boring questions honestly: can I trust my own scoreboard, and which of my calls actually deserve confidence? Those questions don’t care whether the subject is football, freight, or invoices — and in my experience the upgrade to a fancier model gets chased long before either one is answered. If your work runs on forecasts and you’ve never quite trusted the dashboard that grades them, you already know the more interesting problem to chew on — and the honest first move is just to watch the next matchday land on the public page before you take anything I’ve said on faith. If somewhere in here you saw your own world instead of a football pitch, well — you know where to find me.