cat articles/ai-predictions-graded-matchday-2.mdx
Comunio World Cup 2026 · Part 3Round two of the public scorecard: the predictions got sharp — and went quiet about when they're wrong
Round two of grading my World Cup fantasy AI in public: the match-result predictions jumped from 46% to 75% — and the same data shows it got no better at knowing when it's wrong.
Jun 25, 2026 · by Daniel Deusing · ~18 min read #ai #agents #football
In the last article I said I’d do this again after the second round of games — put the predictions up against what actually happened, out loud, misses and all. So here’s round two. It landed somewhere stranger than a clean win or a clean loss.
One thing to be clear about up front, because it’s easy to misread: I’m not training an AI to predict football, and there’s no custom model being built here. I take existing models — the same ones any company can pick off the shelf — and give them the tools, the context, and the instructions to do a specific job, then sharpen how they do it. That’s what applied AI looks like in practice: you don’t build the brain, you put a good one to work on your problem.
I’d changed a pile of things after the first round, and the only way to know whether they actually worked or just read well on the page was to play another round and look. So here’s what the numbers say — both halves of it.
The good news: calling the winner of a game went from 46% right to 75% right. That’s the one number I most wanted to move, and it moved more than I expected.
The catch: the system got much better at being right without getting any better at knowing when it’s wrong. That gap — not the football — is the most useful thing in this whole piece.
Let me walk you through both, misses on the table.
What actually got better, and by how much
First, the recap, in case you didn’t read the last article — because the whole point is that you can check me.
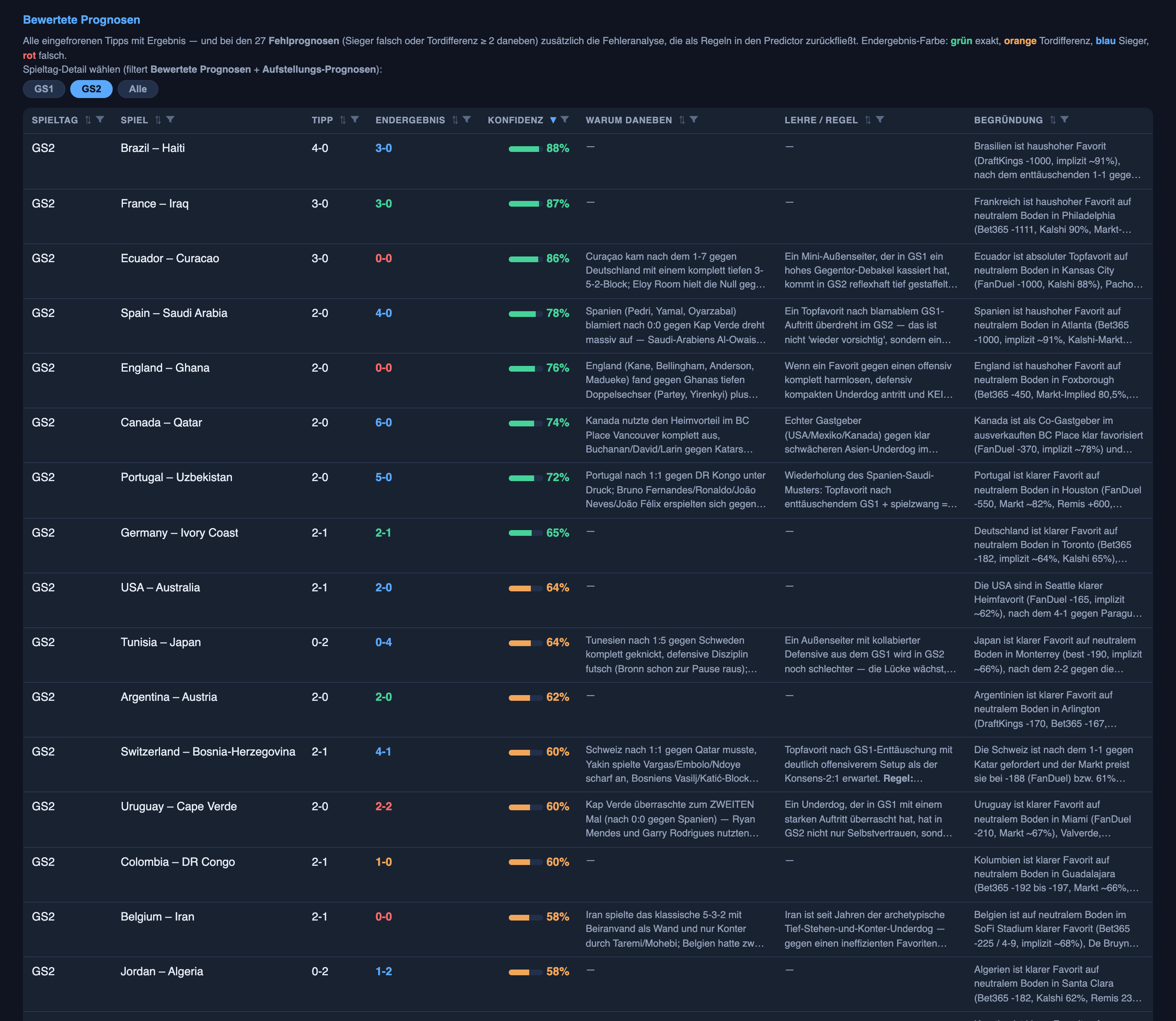
I’m in a fantasy game where a team of AI agents does the daily homework: every matchday, they predict who will start each game and how each game will end, and then reality grades them. In round one the verdict was a clean split. The system was already good at calling who would be in the starting eleven (the knowable part), and plainly bad at calling the scoreline (the chaotic part). It got the winner right only 46% of the time — barely better than flipping a three-sided coin between win, draw and lose.
Round two, same scoring, no excuses:
- Winner correct: 11 of 24 games in round one (46%) → 18 of 24 in round two (75%).
- Goal difference right: 2 of 24 → 5 of 24 — the right margin even when the exact score was off (tipped 2–0, it finished 3–1).
- Exact score correct: 2 of 24 (8%) → 3 of 24 (13%).
- How far off the goals were, on average: basically unchanged (about one goal per side, both rounds).
So the system got much better at picking who wins, better at the margin, a little better at the exact score, and no better at the raw number of goals it expected — which is what you’d expect if it learned something real about football rather than getting lucky. Picking the winner is a question with signal in it. Pinning the precise number of goals in a single low-scoring game is mostly luck, and luck doesn’t learn.
Why it got better — the part that stops being about football
Here’s the mechanism, because this is where it stops being a sports story and starts being a story about any system that’s supposed to get smarter over time.
After round one, an evaluator agent went through every miss and wrote down what it had gotten wrong — not as a data dump, but as a short list of plain-language lessons, each with evidence. Before round two, the agent that makes the predictions read that list and adjusted. That’s the whole loop.
Two of the lessons it wrote after round one — and the honest split of what each did:
- “At a neutral tournament there is no home advantage.” A dumb assumption carried over from normal league football had been quietly handing the team listed first an edge. Deleted. Small fix, real effect.
- “Don’t equate low confidence with few goals — stop hedging the blow-outs.” This one it wrote down and then didn’t follow. In round one it tipped polite 2–0s in games that turned into routs (Germany won 7–1 after a 3–0 tip). In round two it did the same thing — Spain, Portugal and the Netherlands all tipped at a cautious 2–0 or 2–1, then winning 4–0, 5–0 and 5–1. It got the winners; it’s still badly underselling the scale. A lesson on the books isn’t yet a lesson in the bones — and the margins are where this system stays weakest.
You can read every one of these lessons in plain language. That’s the feature, not a nicety. A system whose learning you can inspect and overrule is one you can run inside a company; a black box that “just improves” is one you’ll never get past your auditor. And it cuts both ways — an evaluator can write a lesson that sounds wise and is actually wrong, which is exactly why a human reads the notebook before it feeds the next round.
The catch: getting it right is not the same as knowing your odds
Now the part I didn’t expect, and the reason I’m not popping any champagne.
A prediction comes with a confidence number — “I’m 70% sure of this.” The honest test of that number isn’t whether the call was right. It’s whether the confidence tracks reality.
Here’s what happened to that second virtue between the two rounds:
- Round one: the system was, on average, about 65% confident on the games it got right and 57% on the ones it got wrong. An eight-point gap — modest, but its confidence was leaning the right way.
- Round two: about 64% confident when right and 64% confident when wrong. The gap collapsed to roughly zero.
I broke those per-round splits out of the raw prediction-and-result logs myself — the summary accuracy page blends both rounds into one figure, so this is me showing the working, not asking you to take it on faith.
Read that again. The system nearly doubled its hit rate — and its confidence stopped distinguishing its hits from its misses at all. It got better at the answer and worse at knowing how sure to be.
How can both be true? Because of which games it still got wrong. Most of round two’s misses rhymed: a clear favourite, an underdog packing its box in front of a hot goalkeeper, and a scoreline that wouldn’t break. Three finished 0–0 — Ecuador, tipped to beat Curaçao 3–0; England, tipped to beat Ghana 2–0; Belgium over Iran — and a fourth, the Czechs, were held to a 1–1. (The other two broke differently: Uruguay got pegged back to a 2–2, and Turkey lost outright to Paraguay.) The system was confident on those favourite-held games — reasonably so, on paper — and wrong every time. Confident-and-wrong on a repeating pattern is the worst failure mode a forecaster has, because it doesn’t feel like a guess. It feels like knowledge.
So that pattern is now a hard rule for round three, not a gentle nudge: against a deep-defending underdog with a good keeper, cap the margin, and price in a real chance of a draw — especially if that underdog already nicked a point off someone stronger. Whether the rule works is, again, something you’ll get to check next round rather than take on my word.
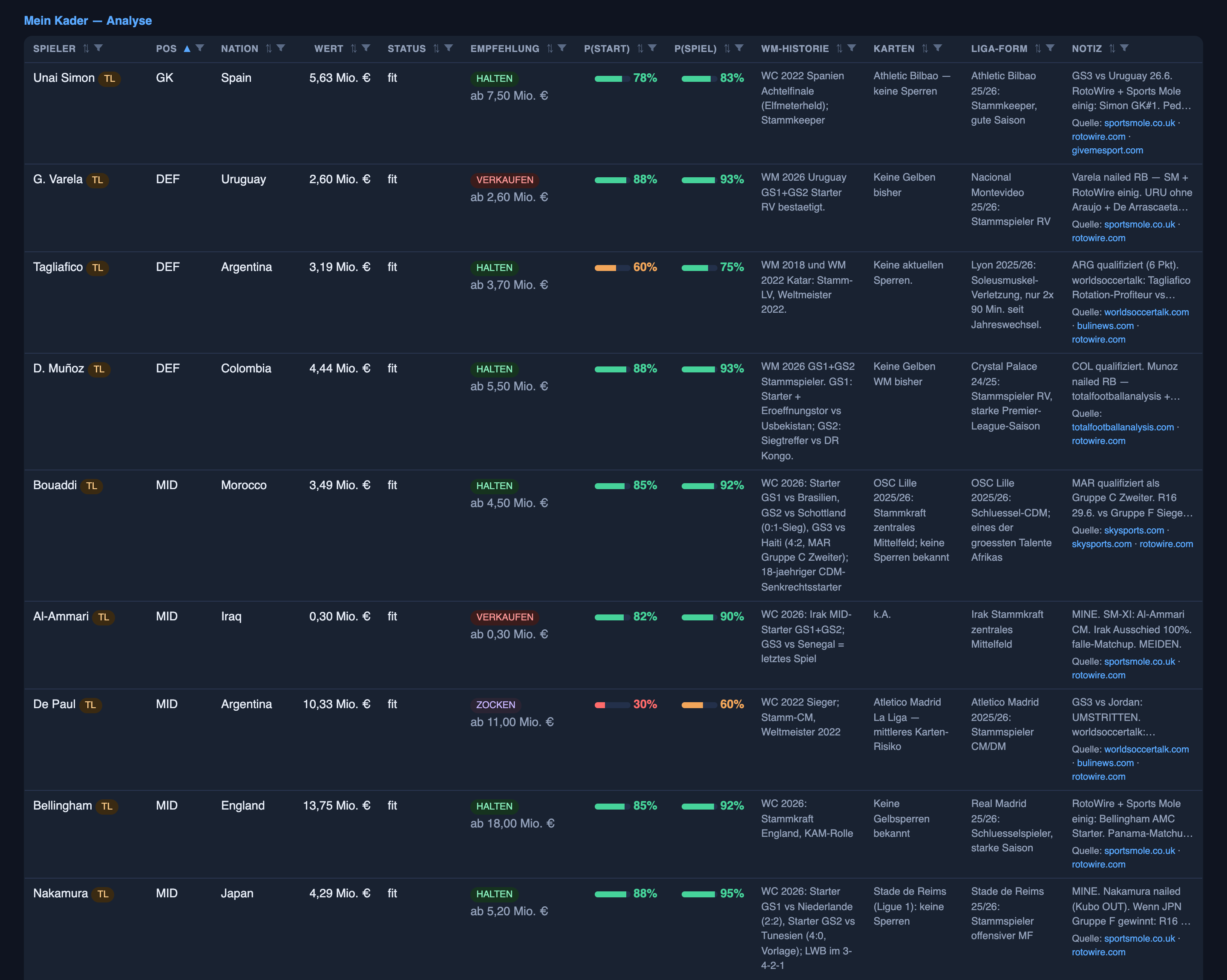
The line-up side: already good, and it stayed good
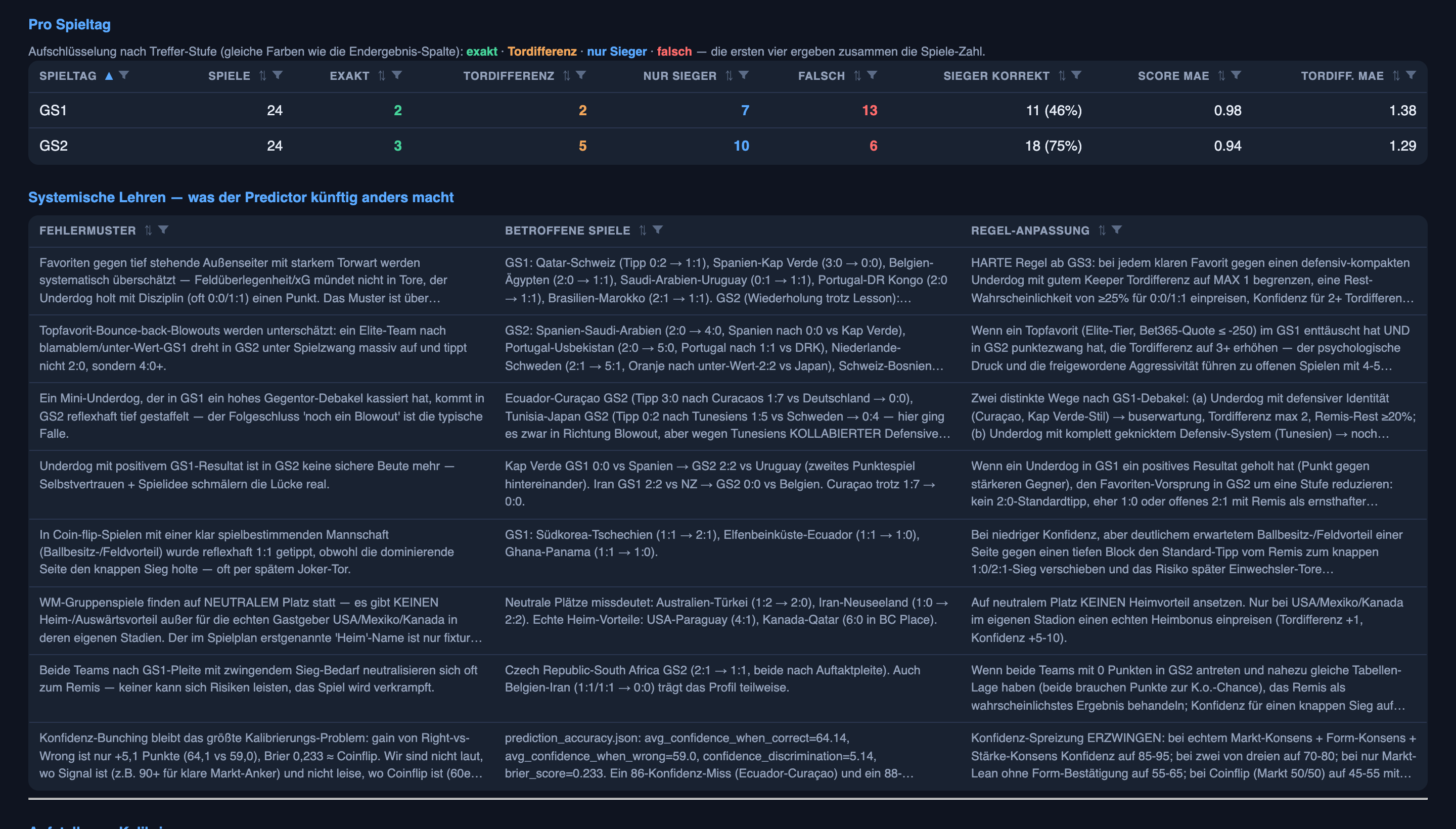
The other half of the system — predicting who actually starts — was the strong half in the last article, and the honest update is undramatic: it stayed strong. Across 357 starting-eleven calls over both rounds (the stale ones thrown out), it was right about 83% of the time, essentially flat round to round.
What did improve is the shape of its confidence. In the last article I flagged that when the system said “quite likely” (the 60–80% band) it ran about eight points too hot. That band is now almost perfectly calibrated — players it puts in that range start almost exactly as often as it says. The stubborn soft spot is still the muddy middle, the 20–40% band: still overconfident — about eleven points hot, down from roughly eighteen in round one. Real progress, not yet a fix.
But round two also surfaced two line-up lessons worth naming, because each is a trap that has nothing to do with football:
- The system trusted a famous name over the current team sheet — and then wrote itself exactly the wrong lesson about it. The keeper is the steadiest position on the pitch, yet the confident keeper calls were among the worst misses: Australia played Beach, a keeper we’d written off at 2%, for all 180 minutes, while the experienced name we’d pencilled in at 90% never got on. The system’s own evaluator filed that under a neat rule — “goalkeeper rotation is the norm at a tournament” — which over-reads a handful of misses into a false pattern; keepers barely rotate. The real miss was a better-known name standing in for the current starter, and the real fix is dull: confirm who’s actually in the eleven, don’t trust the shirt. I deleted the bad lesson before it fed the next round — which is the entire reason a human still reads the notebook.
- The most embarrassing one: a process bug, repeated. Three regular starters we’d lowballed in round one stayed lowballed in round two because their predictions never got refreshed — the exact mistake I described fixing in the last article, applied to the wrong players. The lesson was right; the discipline to apply it to every affected name wasn’t there yet. So the fix this round is mechanical, not clever: before every matchday, force a refresh on any regular starter still sitting at a stale low number. The unglamorous half of the work is, once again, where the real errors hide.
The standings, honestly
You’ll want to know whether any of this is winning. It is — I’m first, on 145 points, nine clear of second, and the most valuable team in the league overall, squad plus cash, by about five million.
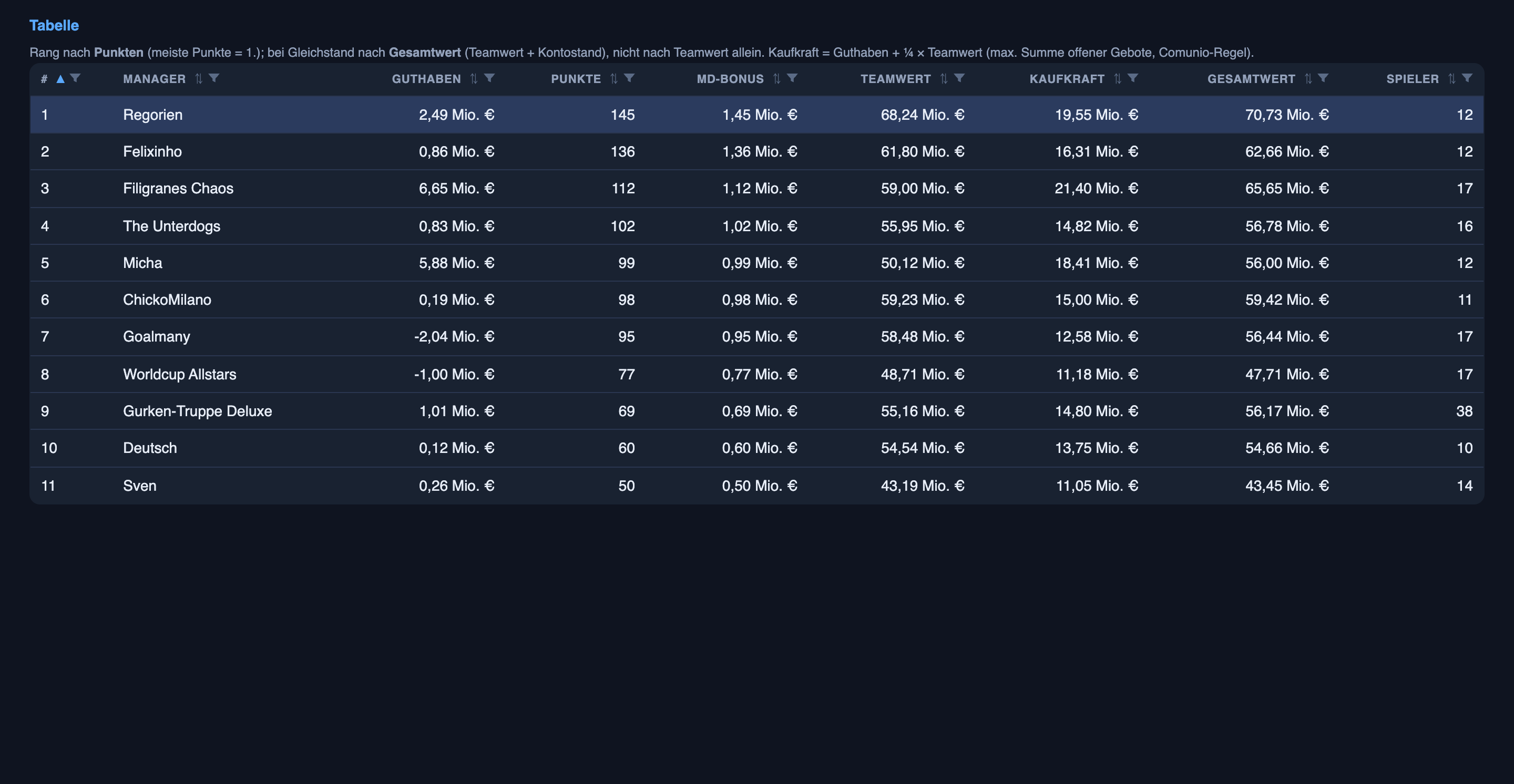
Here’s the honest part: the lead is not coming from the scoreline forecasts. The flashy who-wins-and-by-how-much calls are a useful tool that’s getting sharper, but they’re not what’s winning the league. The edge is the quieter half of the same system. The AI researches every player and predicts who will actually start — the p_start and p_play numbers from earlier — and that knowledge turns into money in the transfer market: I buy cheap players who are quietly nailed-on starters before their price catches up, judge whether a doubtful name is worth a gamble, and bid sharply instead of overpaying. Add a per-point bonus that compounds — more points, more cash, better players, more points — and that’s the real engine. So the AI is a big reason I’m top; just the who-plays research, not the who-wins predictions. The scoreline calls are the public scorecard; the line-up calls are the edge.
What the humans are doing — and what it tells you about any auction
There’s a second dataset hiding in this league that has nothing to do with predictions and everything to do with how people behave when they’re bidding against each other in the dark. Players change hands in a blind auction — sealed bids, nobody sees anyone else’s, highest number wins — and the ledger now holds 639 of those transactions. The patterns in it are the most business-relevant thing I’ve got.
People overpay, almost always. Of the buys with a market-value reference, 85% went above the listed value — the median bid landed about 21% over the player’s market price, the average about 39% over, and one desperate bid came in at nearly five times the listed value. Overpaying isn’t the exception here; it’s the rule. The reason is structural and worth understanding: in a sealed-bid auction you don’t pay what the thing is worth, you pay what you fear the next person will bid — and the owner won’t sell at face value anyway. The “market value” is a reference, not a price.
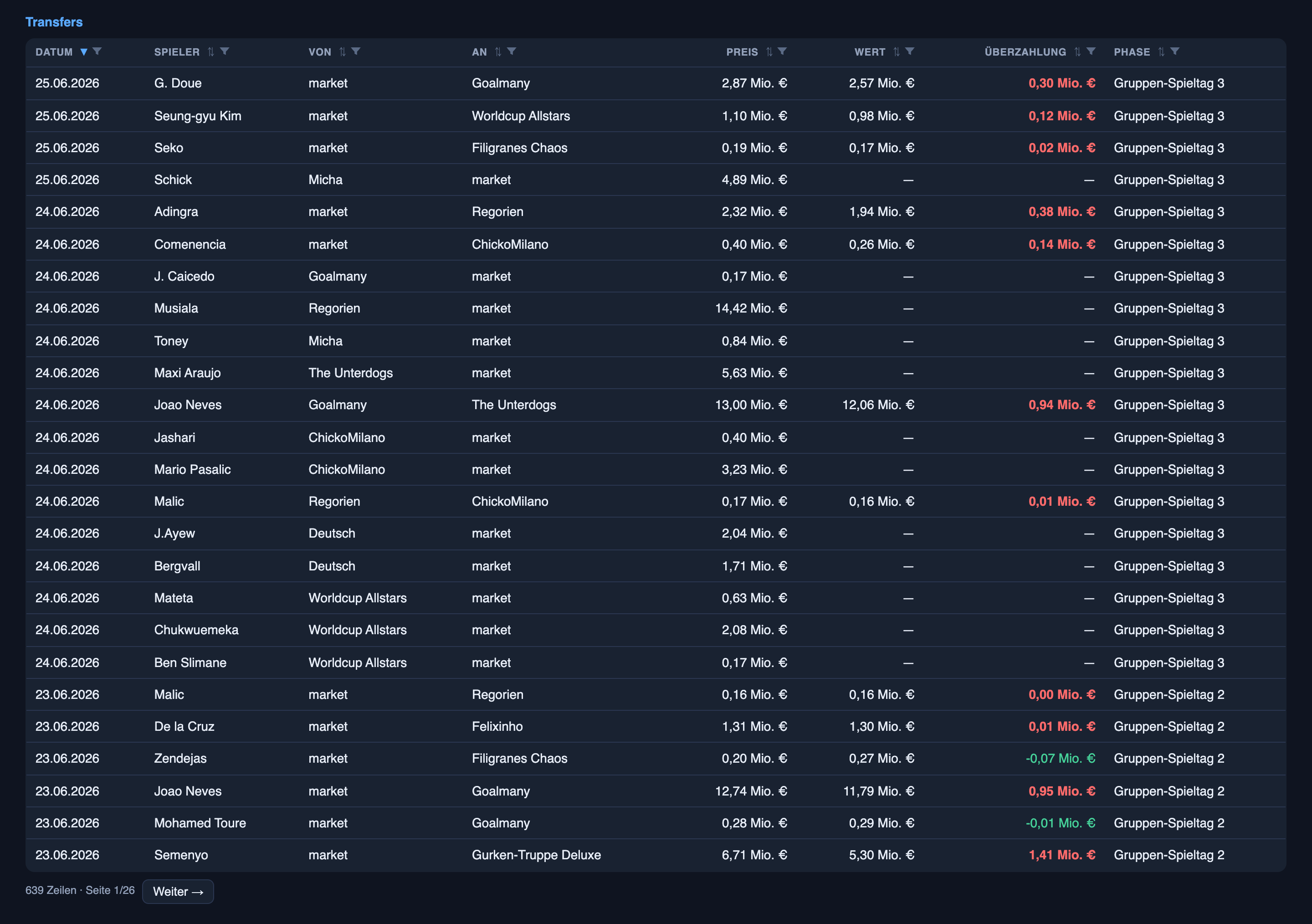
The frenzy front-loads. Activity was heaviest before the tournament kicked off — squad-building season, roughly nineteen moves a day — and then cooled to about fourteen a day once real games started and most squads were set. The over-bidding cooled too: the typical premium shrank once the matches were underway and managers had less reason to chase. People are boldest when the field is wide open and the stakes are still abstract, and more disciplined once the games — and the consequences — are real.
With the knockouts looming, there are already seven open bids on my players sitting in the inbox — the market waking up again.
Two forecasts for what’s coming — said out loud now, graded later
A forecast you make after the fact is worthless. So here are two I’m calling now, before round three and the knockouts — to be scored in public exactly like everything else.
Forecast one — round three will punish anyone trusting a star’s name. Seven teams have already won both their games — Germany, France, Argentina, Mexico, the USA, Colombia and Norway — so they go into the final group game with one foot in the next round and little left to chase. A coach in that spot has every reason to rest key legs for the rounds that matter. My prediction for round three: a wave of surprise rotations from the front-runners, and the line-up model’s job is to catch them early — a star’s p_start should fall not because he’s injured but because his coach is protecting him. The system now treats a team with little left to play for as an explicit rotation flag. We’ll see next round whether that’s enough.
Forecast two — the knockouts will reprice the entire transfer list. After round three the format turns brutal and simple: the field halves each round — 32 teams, then 16, then 8, then 4, then 2 — and from the round of 16 on, every point a player scores counts double.
So here’s the prediction: as the group stage ends and a third of the teams go home, expect a two-sided rush on the transfer list. A sell-off of players from eliminated or fading nations — dead assets nobody wants to be holding — and, at the same time, bidding wars for the nailed starters of the genuine contenders, with the over-bidding I described above getting worse at the top, because a double-scoring knockout starter is worth chasing past any sane price. The managers who move early — before the bracket is obvious — will pay less than the ones who wait for certainty. I’ll report back on whether that’s how it actually played out.
Strip the football out
Read this whole piece again and delete the word “football.”
A forecasting system was rebuilt and it got measurably more accurate — and the very same data showed it had stopped being able to tell you which of its calls to trust. That second fact is the one that should worry you, because a model that’s confidently wrong on a repeating pattern is more dangerous than one that’s honestly unsure. If someone sells you a model that “improved its accuracy to 75%,” the next question isn’t “how high can it go” — it’s “and does it know when it’s about to be wrong?” Track both numbers, or you’ll be confident and wrong at the same time.
The rest maps just as cleanly. The learning that matters wasn’t a bigger model; it was a readable notebook of mistakes a human can audit and overrule — that’s how an AI improvement survives contact with a company. The errors that bit hardest weren’t the AI being clever or dumb; they were boring process failures, like a stale number that never got refreshed. And the human-behaviour data — overpay by default, boldest when the prize is still abstract — is the shape of every competitive bid your business has ever made.
Demand forecasting, churn detection, supplier-risk monitoring, pricing under deadline pressure — same machinery, same traps, the same two questions worth more than any model upgrade: can I trust my own scoreboard, and do my confident calls actually deserve the confidence? The footballers just make the scoreboard public and the stakes low enough to show you the whole thing, misses and all.
A last thought before I let you go. The most useful number this round wasn’t the 75%. It was the confidence gap closing to zero — the system quietly telling me it had learned to win without learning to doubt. I’d rather know that than not. If your work runs on forecasts and you’ve never separated “how often is it right” from “does it know when it isn’t,” that’s the more interesting problem on your desk — and you can watch round three land on the public page before you take a word of this on faith. If somewhere in here you saw your own world instead of a football pitch, you know where to find me.