cat artigos/ai-predictions-graded-matchday-2.mdx
Comunio World Cup 2026 · Parte 3Segunda rodada do placar público: as previsões ficaram afiadas — e ficaram caladas sobre quando estão erradas
Segunda rodada da avaliação pública da minha IA de fantasy da Copa do Mundo: as previsões de resultado de jogo saltaram de 46% para 75% — e os mesmos dados mostram que ela não ficou nem um pouco melhor em saber quando está errada.
25 de jun. de 2026 · por Daniel Deusing · ~20 min de leitura #ai #agents #football
No artigo anterior eu disse que faria isso de novo depois da segunda rodada de jogos — colocar as previsões contra o que realmente aconteceu, em voz alta, com erros e tudo. Então aqui está a segunda rodada. Ela parou em algum lugar mais estranho do que uma vitória limpa ou uma derrota limpa.
Uma coisa que quero deixar clara de cara, porque é fácil interpretar mal: eu não estou treinando uma IA para prever futebol, e não tem nenhum modelo customizado sendo construído aqui. Eu pego modelos existentes — os mesmos que qualquer empresa pode tirar da prateleira — e dou a eles as ferramentas, o contexto e as instruções para fazer um trabalho específico, e depois refino como eles fazem isso. É isso que a IA aplicada parece na prática: você não constrói o cérebro, você coloca um bom cérebro para trabalhar no seu problema.
Eu tinha mudado um monte de coisas depois da primeira rodada, e o único jeito de saber se elas de fato funcionaram ou só ficaram bonitas no papel era jogar mais uma rodada e olhar. Então aqui está o que os números dizem — as duas metades.
A boa notícia: acertar o vencedor de um jogo passou de 46% de acerto para 75% de acerto. Esse é o número que eu mais queria mover, e ele se moveu mais do que eu esperava.
O porém: o sistema ficou muito melhor em estar certo sem ficar nem um pouco melhor em saber quando está errado. Essa lacuna — não o futebol — é a coisa mais útil deste texto inteiro.
Deixa eu te levar pelos dois, com os erros na mesa.
O que de fato melhorou, e em quanto
Primeiro, o resumo, caso você não tenha lido o artigo anterior — porque o ponto central é que você consiga me conferir.
Estou num jogo de fantasy onde um time de agentes de IA faz a lição de casa diária: a cada rodada, eles preveem quem vai começar cada jogo e como cada jogo vai terminar, e então a realidade os avalia. Na primeira rodada o veredito foi uma divisão limpa. O sistema já era bom em acertar quem estaria no time titular (a parte conhecível), e claramente ruim em acertar o placar (a parte caótica). Ele acertou o vencedor só 46% das vezes — mal melhor do que jogar uma moeda de três lados entre vitória, empate e derrota.
Segunda rodada, mesma pontuação, sem desculpas:
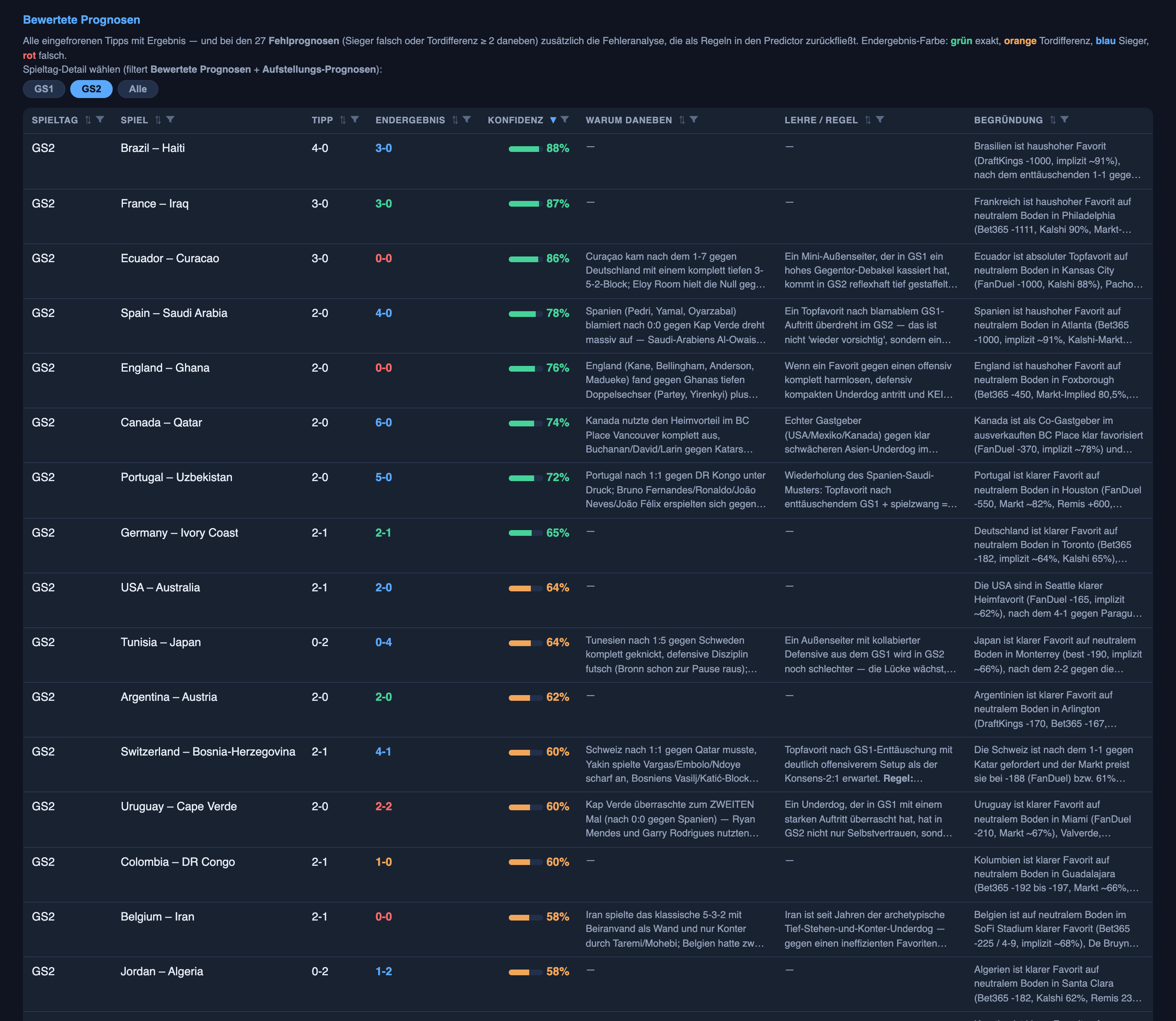
- Vencedor correto: 11 de 24 jogos na primeira rodada (46%) → 18 de 24 na segunda rodada (75%).
- Diferença de gols certa: 2 de 24 → 5 de 24 — a margem certa mesmo quando o placar exato escapou (palpitou 2–0, terminou 3–1).
- Placar exato correto: 2 de 24 (8%) → 3 de 24 (13%).
- Quão longe os gols ficaram, em média: basicamente inalterado (cerca de um gol por lado, nas duas rodadas).
Então o sistema ficou muito melhor em escolher quem vence, melhor na margem, um pouco melhor no placar exato, e nada melhor no número bruto de gols que esperava — que é exatamente o que você esperaria se ele tivesse aprendido algo real sobre futebol em vez de ter dado sorte. Escolher o vencedor é uma pergunta que tem sinal dentro dela. Cravar o número preciso de gols num único jogo de poucos gols é quase pura sorte, e sorte não aprende.
Por que ele melhorou — a parte que deixa de ser sobre futebol
Aqui está o mecanismo, porque é aqui que isso deixa de ser uma história de esporte e começa a ser uma história sobre qualquer sistema que deveria ficar mais inteligente com o tempo.
Depois da primeira rodada, um agente avaliador passou por cada erro e anotou o que tinha errado — não como um despejo de dados, mas como uma lista curta de lições em linguagem simples, cada uma com evidência. Antes da segunda rodada, o agente que faz as previsões leu essa lista e se ajustou. É esse o loop inteiro.
Duas das lições que ele escreveu depois da primeira rodada — e a divisão honesta do que cada uma fez:
- “Num torneio em campo neutro não existe fator casa.” Uma suposição boba herdada do futebol normal de liga vinha discretamente dando uma vantagem ao time listado primeiro. Apagada. Correção pequena, efeito real.
- “Não confunda baixa confiança com poucos gols — pare de hedgear as goleadas.” Essa ele anotou e depois não seguiu. Na primeira rodada ele palpitou educados 2–0 em jogos que viraram massacres (a Alemanha venceu por 7–1 depois de um palpite de 3–0). Na segunda rodada ele fez a mesma coisa — Espanha, Portugal e Holanda todos com palpite cauteloso de 2–0 ou 2–1, e depois vencendo por 4–0, 5–0 e 5–1. Ele acertou os vencedores; ainda está subestimando feio a escala. Uma lição no papel ainda não é uma lição nos ossos — e as margens são onde esse sistema continua mais fraco.
Você consegue ler cada uma dessas lições em linguagem simples. Esse é o recurso, não um mimo. Um sistema cujo aprendizado você consegue inspecionar e vetar é um que você pode rodar dentro de uma empresa; uma caixa-preta que “simplesmente melhora” é uma que você nunca vai conseguir passar pelo seu auditor. E isso corta para os dois lados — um avaliador pode escrever uma lição que soa sábia e na verdade está errada, que é exatamente por que um humano lê o caderno antes de ele alimentar a rodada seguinte.
O porém: acertar não é o mesmo que conhecer suas probabilidades
Agora a parte que eu não esperava, e a razão pela qual não estou abrindo nenhum champanhe.
Uma previsão vem com um número de confiança — “estou 70% certo disso”. O teste honesto desse número não é se o palpite estava certo. É se a confiança acompanha a realidade.
Aqui está o que aconteceu com essa segunda virtude entre as duas rodadas:
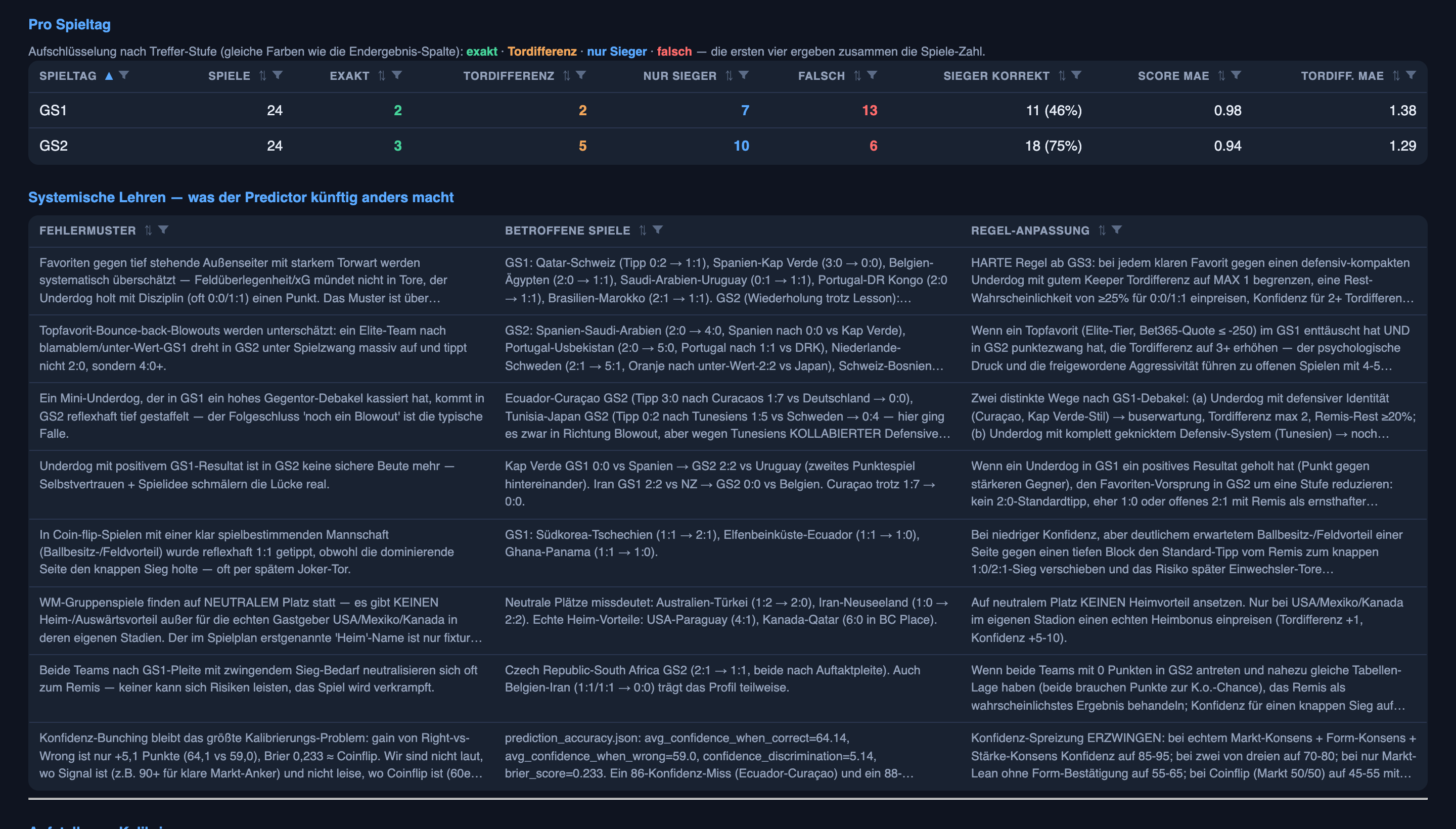
- Primeira rodada: o sistema estava, em média, cerca de 65% confiante nos jogos que acertou e 57% nos que errou. Uma lacuna de oito pontos — modesta, mas a confiança estava pendendo para o lado certo.
- Segunda rodada: cerca de 64% confiante quando certo e 64% confiante quando errado. A lacuna desabou para basicamente zero.
Eu mesmo separei essas divisões por rodada a partir dos logs brutos de previsão-e-resultado — a página de resumo de acurácia mistura as duas rodadas numa única cifra, então isto sou eu mostrando a conta feita, não pedindo que você acredite na fé.
Leia de novo. O sistema quase dobrou sua taxa de acerto — e a confiança dele parou completamente de distinguir os acertos dos erros. Ele ficou melhor na resposta e pior em saber quão certo deveria estar.
Como as duas coisas podem ser verdade? Por causa de quais jogos ele ainda errou. A maioria dos erros da segunda rodada rimava: um claro favorito, um azarão fechado na própria área na frente de um goleiro inspirado, e um placar que não se quebrava. Três terminaram 0–0 — Equador, com palpite de vencer Curaçao por 3–0; Inglaterra, com palpite de vencer Gana por 2–0; Bélgica sobre o Irã — e um quarto, os tchecos, segurados num 1–1. (Os outros dois quebraram de outro jeito: o Uruguai foi alcançado num 2–2, e a Turquia perdeu de vez para o Paraguai.) O sistema estava confiante nesses jogos de favorito-segurado — razoavelmente, no papel — e errou todas. Confiante-e-errado num padrão que se repete é o pior modo de falha que um previsor tem, porque não parece um palpite. Parece conhecimento.
Então esse padrão agora é uma regra dura para a terceira rodada, não um empurrãozinho gentil: contra um azarão de defesa fechada com um bom goleiro, limite a margem e precifique uma chance real de empate — especialmente se esse azarão já roubou um ponto de alguém mais forte. Se a regra funciona é, de novo, algo que você vai poder conferir na próxima rodada em vez de acreditar na minha palavra.
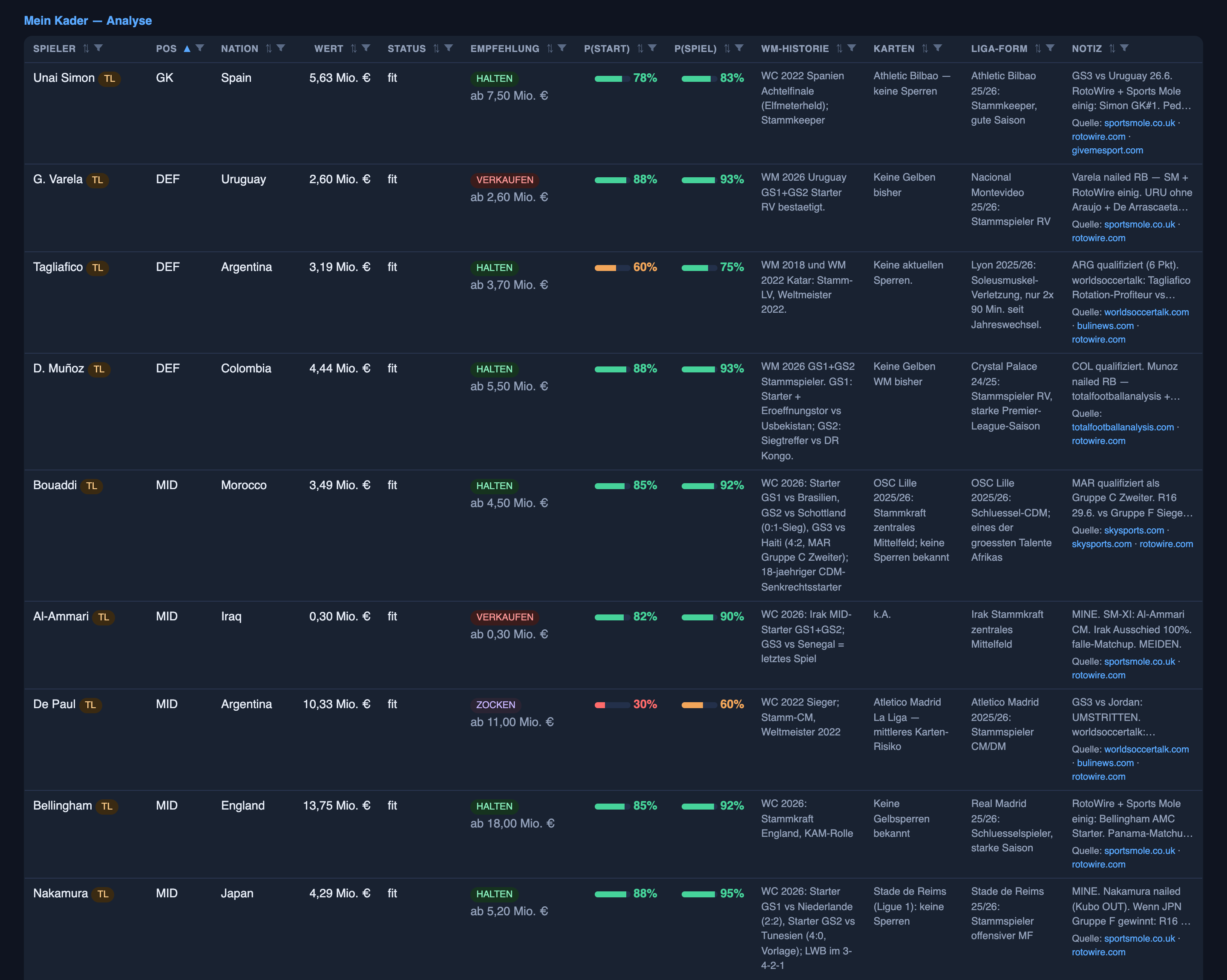
O lado da escalação: já bom, e continuou bom
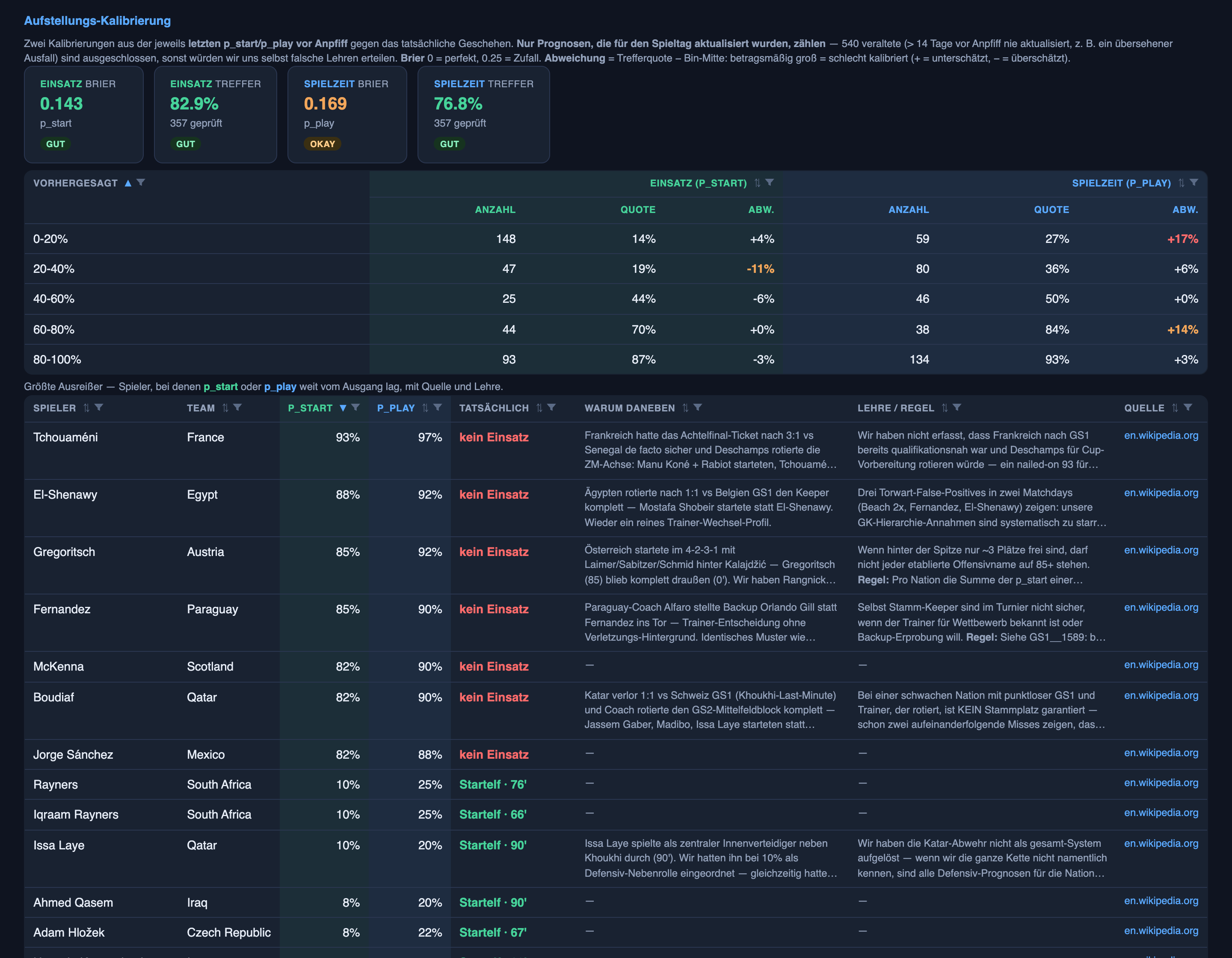
A outra metade do sistema — prever quem de fato começa — era a metade forte no artigo anterior, e a atualização honesta é sem drama: continuou forte. Ao longo de 357 palpites de time titular nas duas rodadas (os vencidos descartados), ele acertou cerca de 83% das vezes, essencialmente estável de uma rodada para a outra.
O que de fato melhorou foi o formato da confiança dele. No artigo anterior eu sinalizei que quando o sistema dizia “bem provável” (a faixa de 60–80%) ele estava cerca de oito pontos quente demais. Essa faixa agora está quase perfeitamente calibrada — os jogadores que ele coloca nessa faixa começam quase exatamente com a frequência que ele diz. O ponto fraco teimoso ainda é o meio lamacento, a faixa de 20–40%: ainda confiante demais — cerca de onze pontos quente, contra uns dezoito na primeira rodada. Progresso real, ainda não uma cura.
Mas a segunda rodada também trouxe à tona duas lições de escalação que vale nomear, porque cada uma é uma armadilha que não tem nada a ver com futebol:
- O sistema confiou num nome famoso em vez da escalação atual — e depois escreveu para si mesmo exatamente a lição errada sobre isso. O goleiro é a posição mais estável dentro de campo, e ainda assim os palpites confiantes de goleiro estavam entre os piores erros: a Austrália escalou Beach, um goleiro que tínhamos descartado a 2%, pelos 180 minutos inteiros, enquanto o nome experiente que tínhamos marcado a 90% nunca entrou. O próprio avaliador do sistema arquivou isso sob uma regra arrumadinha — “a rotação de goleiros é a norma num torneio” — que sobre-lê um punhado de erros num padrão falso; goleiros mal rodam. O erro real foi um nome mais conhecido entrando no lugar do titular atual, e a correção real é entediante: confirme quem de fato está no time, não confie na camisa. Eu apaguei a lição ruim antes que ela alimentasse a rodada seguinte — que é a razão inteira de um humano ainda ler o caderno.
- O mais constrangedor: um bug de processo, repetido. Três titulares regulares que tínhamos subestimado na primeira rodada continuaram subestimados na segunda rodada porque suas previsões nunca foram atualizadas — exatamente o erro que descrevi corrigir no artigo anterior, aplicado aos jogadores errados. A lição estava certa; a disciplina de aplicá-la a cada nome afetado ainda não estava lá. Então a correção desta rodada é mecânica, não esperta: antes de cada rodada, force uma atualização em qualquer titular regular ainda parado num número baixo desatualizado. A metade sem glamour do trabalho é, mais uma vez, onde os erros de verdade se escondem.
A classificação, honestamente
Você vai querer saber se algo disso está ganhando. Está — estou em primeiro, com 145 pontos, nove à frente do segundo, e o time mais valioso da liga no geral, elenco mais dinheiro, por cerca de cinco milhões.
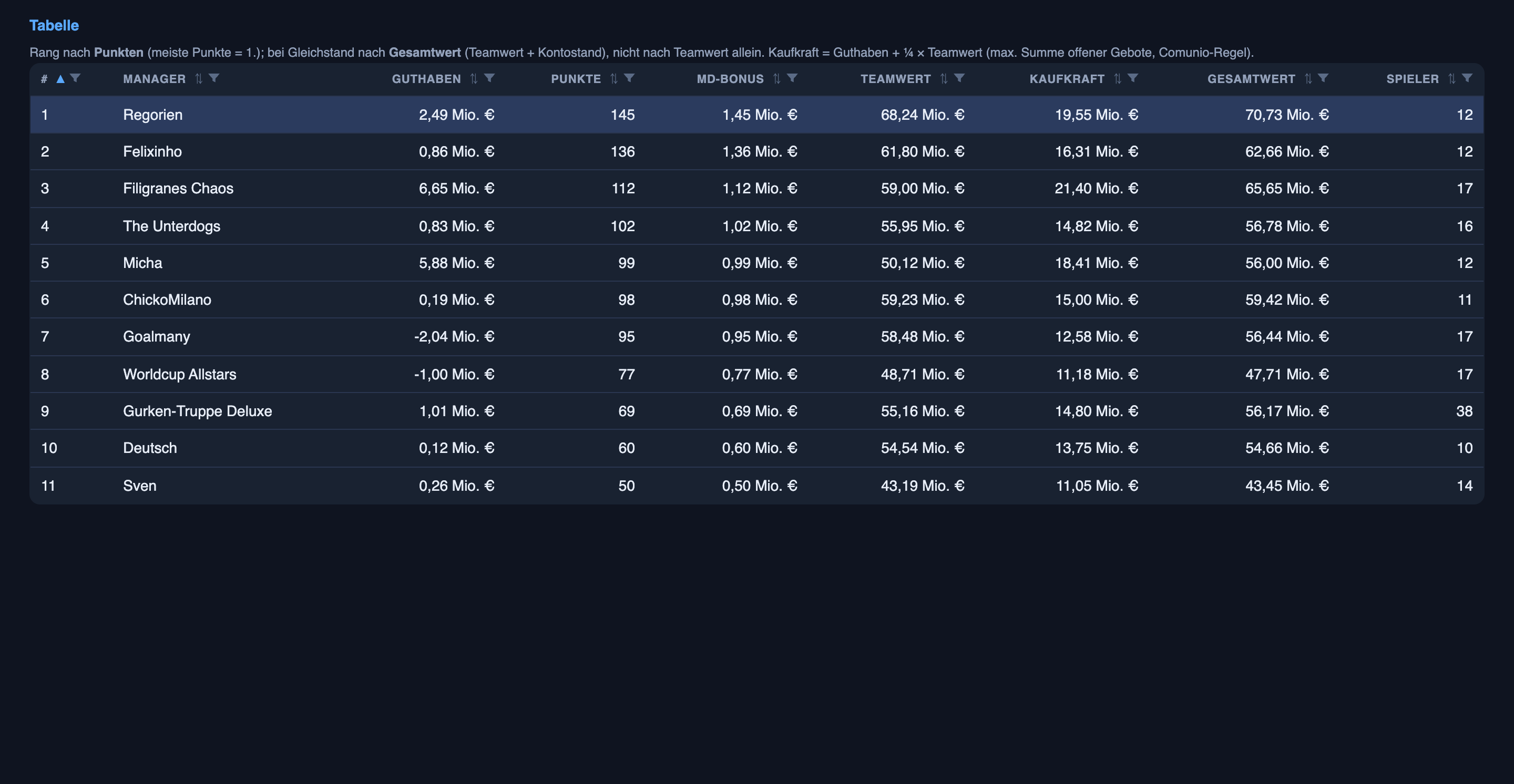
Aqui está a parte honesta: a liderança não está vindo das previsões de placar. Os palpites chamativos de quem-vence-e-por-quanto são uma ferramenta útil que está ficando mais afiada, mas não são o que está ganhando a liga. A vantagem é a metade mais quieta do mesmo sistema. A IA pesquisa cada jogador e prevê quem de fato vai começar — os números de p_start e p_play de antes — e esse conhecimento vira dinheiro no mercado de transferências: eu compro jogadores baratos que são titulares discretamente garantidos antes de o preço deles alcançar, julgo se um nome duvidoso vale a aposta, e dou lances afiados em vez de pagar demais. Some um bônus por ponto que se acumula — mais pontos, mais dinheiro, jogadores melhores, mais pontos — e esse é o motor de verdade. Então a IA é uma grande razão de eu estar em primeiro; só que a pesquisa de quem-joga, não as previsões de quem-vence. Os palpites de placar são o placar público; os palpites de escalação são a vantagem.
O que os humanos estão fazendo — e o que isso te diz sobre qualquer leilão
Tem um segundo conjunto de dados escondido nesta liga que não tem nada a ver com previsões e tudo a ver com como as pessoas se comportam quando estão dando lances umas contra as outras no escuro. Jogadores trocam de mãos num leilão cego — lances selados, ninguém vê o de ninguém, o maior número vence — e o registro agora guarda 639 dessas transações. Os padrões nele são a coisa mais relevante para negócios que eu tenho.
As pessoas pagam demais, quase sempre. Das compras com uma referência de valor de mercado, 85% ficaram acima do valor listado — o lance mediano caiu cerca de 21% acima do preço de mercado do jogador, o médio cerca de 39% acima, e um lance desesperado chegou a quase cinco vezes o valor listado. Pagar demais não é a exceção aqui; é a regra. A razão é estrutural e vale entender: num leilão de lance selado você não paga o que a coisa vale, você paga o que teme que a próxima pessoa vá dar de lance — e o dono não vai vender pelo valor de face de qualquer jeito. O “valor de mercado” é uma referência, não um preço.
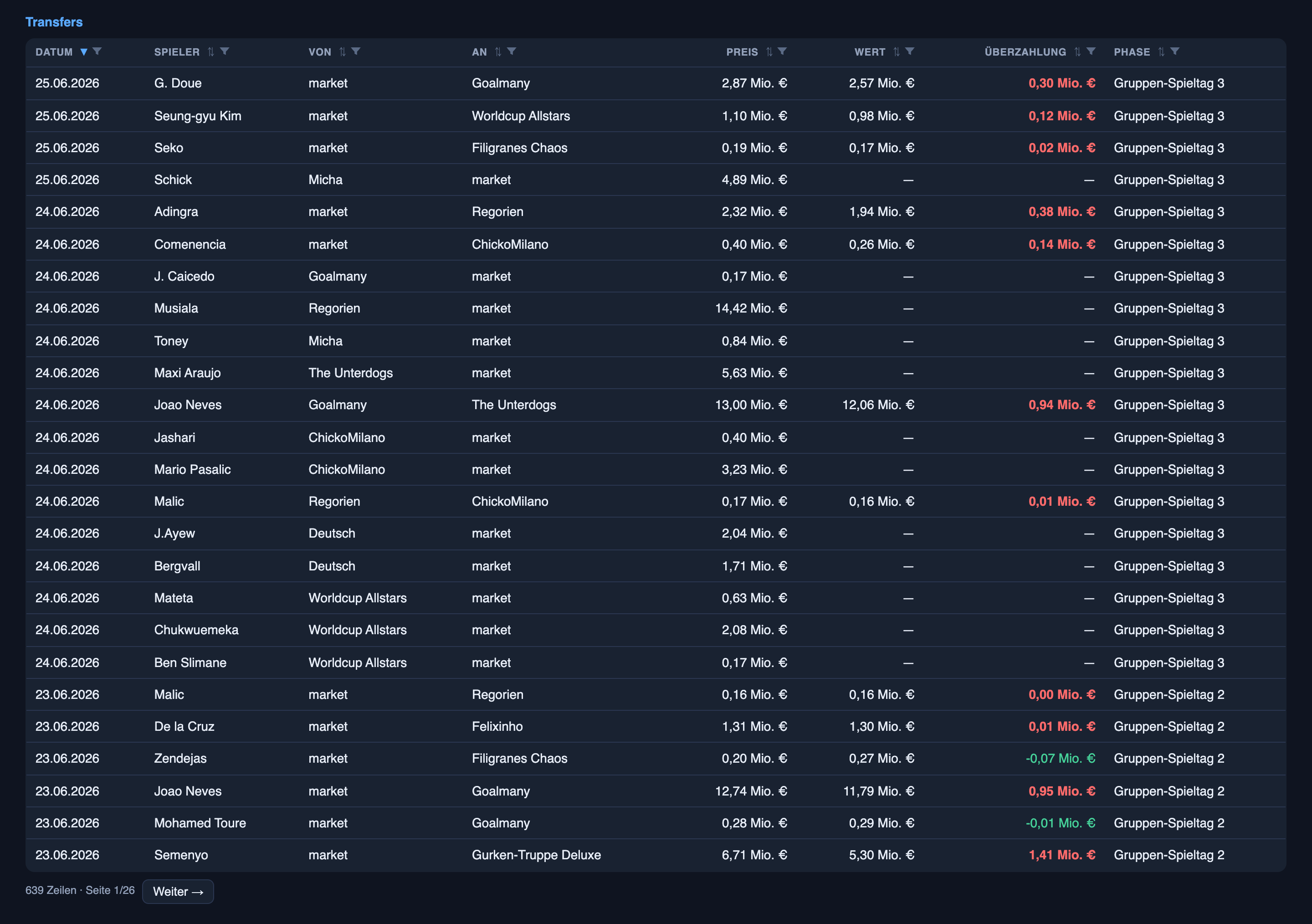
O frenesi concentra-se no começo. A atividade foi mais pesada antes de o torneio começar — temporada de montagem de elenco, cerca de dezenove movimentos por dia — e depois esfriou para cerca de quatorze por dia quando os jogos de verdade começaram e a maioria dos elencos já estava fechada. O excesso de lances esfriou também: o ágio típico encolheu assim que as partidas começaram e os managers tinham menos razão para correr atrás. As pessoas são mais ousadas quando o campo está totalmente aberto e o que está em jogo ainda é abstrato, e mais disciplinadas quando os jogos — e as consequências — são reais.
Com os mata-matas se aproximando, já tem sete lances abertos pelos meus jogadores parados na caixa de entrada — o mercado acordando de novo.
Duas previsões para o que vem — ditas em voz alta agora, avaliadas depois
Uma previsão que você faz depois do fato não vale nada. Então aqui estão duas que eu cravo agora, antes da terceira rodada e dos mata-matas — para serem pontuadas em público exatamente como tudo o mais.
Previsão um — a terceira rodada vai punir quem confiar no nome de uma estrela. Sete times já venceram os dois jogos — Alemanha, França, Argentina, México, EUA, Colômbia e Noruega — então eles entram no último jogo da fase de grupos com um pé na fase seguinte e pouco a perseguir. Um técnico nessa situação tem todas as razões para poupar pernas importantes para as fases que importam. Minha previsão para a terceira rodada: uma onda de rotações surpresa dos líderes, e o trabalho do modelo de escalação é pegá-las cedo — o p_start de uma estrela deveria cair não porque ele está lesionado, mas porque o técnico está protegendo ele. O sistema agora trata um time com pouco a jogar como uma bandeira explícita de rotação. Vamos ver na próxima rodada se isso basta.
Previsão dois — os mata-matas vão reprecificar toda a lista de transferências. Depois da terceira rodada o formato fica brutal e simples: o campo cai pela metade a cada fase — 32 times, depois 16, depois 8, depois 4, depois 2 — e a partir das oitavas, cada ponto que um jogador faz conta em dobro.
Então aqui está a previsão: conforme a fase de grupos termina e um terço dos times vai para casa, espere uma corrida de dois lados na lista de transferências. Uma liquidação de jogadores de nações eliminadas ou em queda — ativos mortos que ninguém quer estar segurando — e, ao mesmo tempo, guerras de lances pelos titulares garantidos dos verdadeiros candidatos, com o excesso de lances que descrevi acima ficando pior no topo, porque um titular de mata-mata que pontua em dobro vale ser perseguido além de qualquer preço sensato. Os managers que se mexem cedo — antes de o chaveamento ficar óbvio — vão pagar menos do que os que esperam pela certeza. Vou voltar para contar se foi assim que aconteceu na prática.
Tire o futebol
Leia este texto inteiro de novo e apague a palavra “futebol”.
Um sistema de previsão foi reconstruído e ficou mensuravelmente mais acurado — e os mesmíssimos dados mostraram que ele tinha deixado de conseguir te dizer em quais dos seus palpites confiar. Esse segundo fato é o que deveria te preocupar, porque um modelo que está confiantemente errado num padrão que se repete é mais perigoso do que um que está honestamente em dúvida. Se alguém te vende um modelo que “melhorou sua acurácia para 75%”, a próxima pergunta não é “quão alto ele pode chegar” — é “e ele sabe quando está prestes a errar?” Acompanhe os dois números, ou você vai estar confiante e errado ao mesmo tempo.
O resto mapeia com a mesma limpeza. O aprendizado que importou não foi um modelo maior; foi um caderno legível de erros que um humano consegue auditar e vetar — é assim que uma melhoria de IA sobrevive ao contato com uma empresa. Os erros que mais doeram não foram a IA sendo esperta ou burra; foram falhas chatas de processo, como um número desatualizado que nunca foi atualizado. E os dados de comportamento humano — pagar demais por padrão, mais ousado quando o prêmio ainda é abstrato — são o formato de todo lance competitivo que o seu negócio já fez.
Previsão de demanda, detecção de churn, monitoramento de risco de fornecedor, precificação sob pressão de prazo — a mesma maquinaria, as mesmas armadilhas, as mesmas duas perguntas que valem mais do que qualquer upgrade de modelo: posso confiar no meu próprio placar, e meus palpites confiantes de fato merecem a confiança? Os jogadores de futebol só tornam o placar público e o que está em jogo baixo o suficiente para te mostrar a coisa toda, com erros e tudo.
Um último pensamento antes de te liberar. O número mais útil desta rodada não foi os 75%. Foi a lacuna de confiança fechando para zero — o sistema me dizendo, quietinho, que tinha aprendido a vencer sem aprender a duvidar. Eu prefiro saber disso a não saber. Se o seu trabalho roda em previsões e você nunca separou “com que frequência ela está certa” de “ela sabe quando não está”, esse é o problema mais interessante na sua mesa — e você pode ver a terceira rodada chegar na página pública antes de acreditar numa palavra disto na fé. Se em algum ponto daqui você viu o seu próprio mundo em vez de um campo de futebol, você sabe onde me encontrar.