cat artigos/ai-predictions-graded-matchday-1.mdx
Comunio World Cup 2026 · Parte 2Previsões, avaliadas com honestidade: boas para acertar quem joga, fracas para acertar o placar
Avalio em público as previsões dos meus agentes de IA na Copa de 2026: ótimas para prever quem é titular, fracas para o placar — e por que essa diferença vale para qualquer empresa.
22 de jun. de 2026 · por Daniel Deusing · ~24 min de leitura #ai #agents #football
No primeiro artigo eu escrevi sobre um time de agentes de IA que montei para jogar uma liga de fantasy da Copa do Mundo de 2026, e fiz uma promessa: eu voltaria depois das partidas e avaliaria as previsões em público — de verdade, com os erros à mostra, não só os acertos. A primeira rodada de jogos da fase de grupos acabou. Aqui está o boletim.
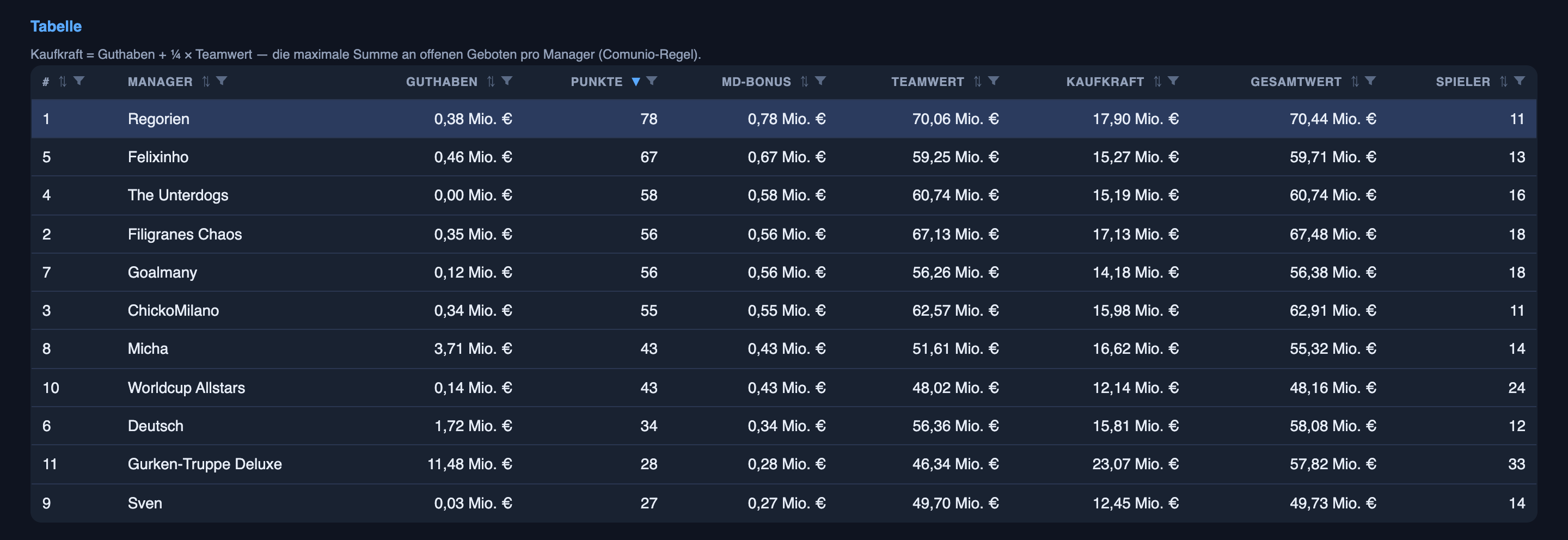
O elenco em si vai bem — está perto do topo da nossa liguinha de amigos depois de uma rodada. Mas quero ser honesto sobre o porquê: isso vem em grande parte da compra-e-venda da parte um, não das previsões dos jogos. As previsões são uma história diferente, mais interessante — e a manchete é uma divisão que eu não esperava:
A parte chamativa — acertar placares — é, por enquanto, aquela em que ele é menos bom. A parte sem glamour — acertar quem vai estar de fato no time titular — é onde ele já é confiável. A razão honesta para essa diferença não é que uma lê dados e a outra chuta — ambas se apoiam em dados (notícias dos times e vazamentos de escalação para o time titular; mercados de apostas e forma para os placares) e ambas envolvem chute de verdade. A diferença é o quanto da resposta já está resolvido antes do apito inicial. Quem é titular já está em grande parte decidido com antecedência, então boa informação te leva longe — fora a eventual surpresa do treinador, que não dá para ler de fora. Um placar é decidido em grande parte ao longo de noventa minutos de caos, então até a melhor informação só estreita o leque; não consegue cravar. Mesmo sistema, dois problemas com quantidades muito diferentes de sorte embutida — e essa distinção, não o futebol, é a parte útil.
Mas, antes de qualquer nota, uma confissão sobre a própria avaliação — porque é aí que está a primeira lição de verdade.
Recapitulando rápido, caso você tenha perdido a parte um: estou num jogo de fantasy onde você compra e vende jogadores de futebol reais num leilão às cegas — lances fechados, ninguém vê o do outro, o maior número ganha — e um time de agentes de IA faz a lição de casa diária. Este artigo é sobre a outra promessa que fiz lá: que o sistema avaliaria as próprias previsões contra a realidade, em público, a partir da noite do primeiro apito.
Tive que consertar o avaliador antes de poder confiar nele
Aqui está a parte que é fácil pular. Quando os primeiros resultados chegaram, minha reluzente página de precisão produziu números em que eu não conseguia confiar — não porque as previsões fossem boas ou ruins, mas porque a avaliação tinha bugs. Três deles valem ser nomeados, porque cada um é um erro que qualquer empresa comete na primeira vez que tenta medir um sistema de IA com honestidade.
Ele avaliou previsões vencidas. Um dos meus jogadores, o meio-campista austríaco Laimer, estava na avaliação marcado como “não vai jogar” com 95% — e aí jogou os noventa minutos inteiros. O sistema parecia muito errado. Mas ele não estava errado nesta semana: esses 95% eram um palpite de três semanas atrás que nunca foi atualizado antes da partida. Eu estava avaliando uma previsão que o sistema tinha basicamente esquecido que fez. Lixo entra, nota lixo.
Ele não conseguia distinguir duas pessoas. Três jogadores — incluindo um zagueiro da Inglaterra chamado O’Reilly — foram marcados como “não jogaram” quando, na verdade, tinham começado a partida inteira. A razão é entediante e importante: o jogador nos dados da escalação ao vivo e o jogador na minha previsão eram o mesmo ser humano, registrado sob dois nomes ligeiramente diferentes, e o sistema os tratou como desconhecidos. É uma falha clássica de resolução de entidades.
Ele deu vantagem de mando num torneio sem jogos em casa. O modelo, sem alarde, entregou ao time listado em primeiro uma vantagem de jogar em casa — mas os jogos da fase de grupos da Copa do Mundo são disputados em campo neutro (fora os anfitriões). Uma pequena suposição, herdada do futebol comum de liga, distorcendo tudo de forma silenciosa.
Repare no que esses três têm em comum: nenhum deles foi a IA sendo “burra”. Os agentes fizeram mais ou menos o que mandaram. As falhas estavam na medição — o encanamento que decide o que conta como certo. E essa é a lição que eu sublinharia para qualquer um que vá apostar orçamento de verdade num projeto de IA: construir a coisa é a metade fácil. Construir uma régua em que você possa de fato confiar é a metade difícil, e é a metade que costuma ser pulada. Um número que você não consegue defender é pior do que nenhum número, porque te deixa confiante e errado ao mesmo tempo.
Os consertos foram quase todos entediantes, e esse é justamente o ponto. Uma trava contra previsões vencidas — um trecho de código simples, sem IA, que descarta qualquer previsão não atualizada para a rodada que está sendo avaliada — agora roda a cada ciclo, e um conjunto novo de previsões é fechado na manhã de cada jogo (chega de fantasmas de 21 dias). Um mapa de apelidos em crescimento — uma tabela de equivalências de nomes — ensina o sistema que “Nico O’Reilly” e “O’Reilly” são um homem só. A regra do campo neutro agora está escrita. As escalações são checadas contra o artigo da partida correspondente na Wikipedia — renderizado no servidor, rápido, com os onze confirmados e os reservas algumas horas depois do apito final, cada divergência citando sua fonte. E os resultados agora recebem um código honesto de quatro cores, que você vai ver abaixo. O princípio por baixo de tudo isso: use a ferramenta cara e inteligente (a IA) só onde o julgamento é genuinamente necessário, e a envolva com código barato, entediante e inquebrável em todo lugar onde uma garantia importa.
A boa notícia: quem vai jogar é em grande parte cognoscível — e lemos bem
Agora as notas. Vamos começar pelo que funcionou, porque me surpreendeu o quão bem funcionou.
Todo dia, para cada jogador, o sistema produz um número que ele chama de p_start. Aí a partida acontece, e a gente confere.
A forma certa de julgar uma nota de confiança não é “estava certa”. É a calibração.
Contra essa régua, o sistema foi bem. Em 172 palpites de time titular na rodada de abertura (os vencidos descartados), ele acertou 84% das vezes — mas o formato importa mais do que a manchete:
- Quando ele dizia que um jogador tinha 0–20% de chance de ser titular (71 palpites), eles foram titulares cerca de 13% das vezes. Quase no ponto certo nos azarões.
- Quando dizia 80–100% (44 palpites), eles foram titulares 91% das vezes. Quando esse sistema está confiante, dá para acreditar.
- O ponto fraco era o meio nebuloso. Na faixa de 20–40% (só 24 palpites) ele sugeria mais ou menos uma chance em três, mas esses jogadores foram titulares só cerca de uma vez em oito — claramente confiante demais.

Uma ressalva justa: isto é uma rodada, e algumas faixas têm só algumas dúzias de palpites, então leia como um sinal a observar, não um veredito gravado em pedra. Mas por que esta é a metade mais firme? Porque quem é titular é em grande parte cognoscível com antecedência: notícias do time, uma coletiva de imprensa, os hábitos de um treinador, um boletim médico. A maior parte do trabalho é leitura disciplinada — reunir o que já é público, mais rápido e mais consistentemente do que eu faria à mão — e só uma fatia é chute genuíno: as decisões de rodízio, o treinador que apronta uma surpresa que nenhuma leitura de escalação pegaria. Essa mistura é exatamente o que a calibração mostra: a leitura é o motivo de as faixas confiantes acertarem, o chute é o motivo de a faixa do meio oscilar.
O que ele acertou e errou sobre os meus próprios jogadores
Calibração abstrata é uma coisa. Aqui está o que ela de fato significou para jogadores que tive, com quem ganhei e com quem perdi — o balanço honesto. Cada palpite vive na mesma tela diária: cada jogador com uma probabilidade de ser titular, uma probabilidade de jogar, um veredito de manter-ou-vender e uma nota que linka suas fontes.
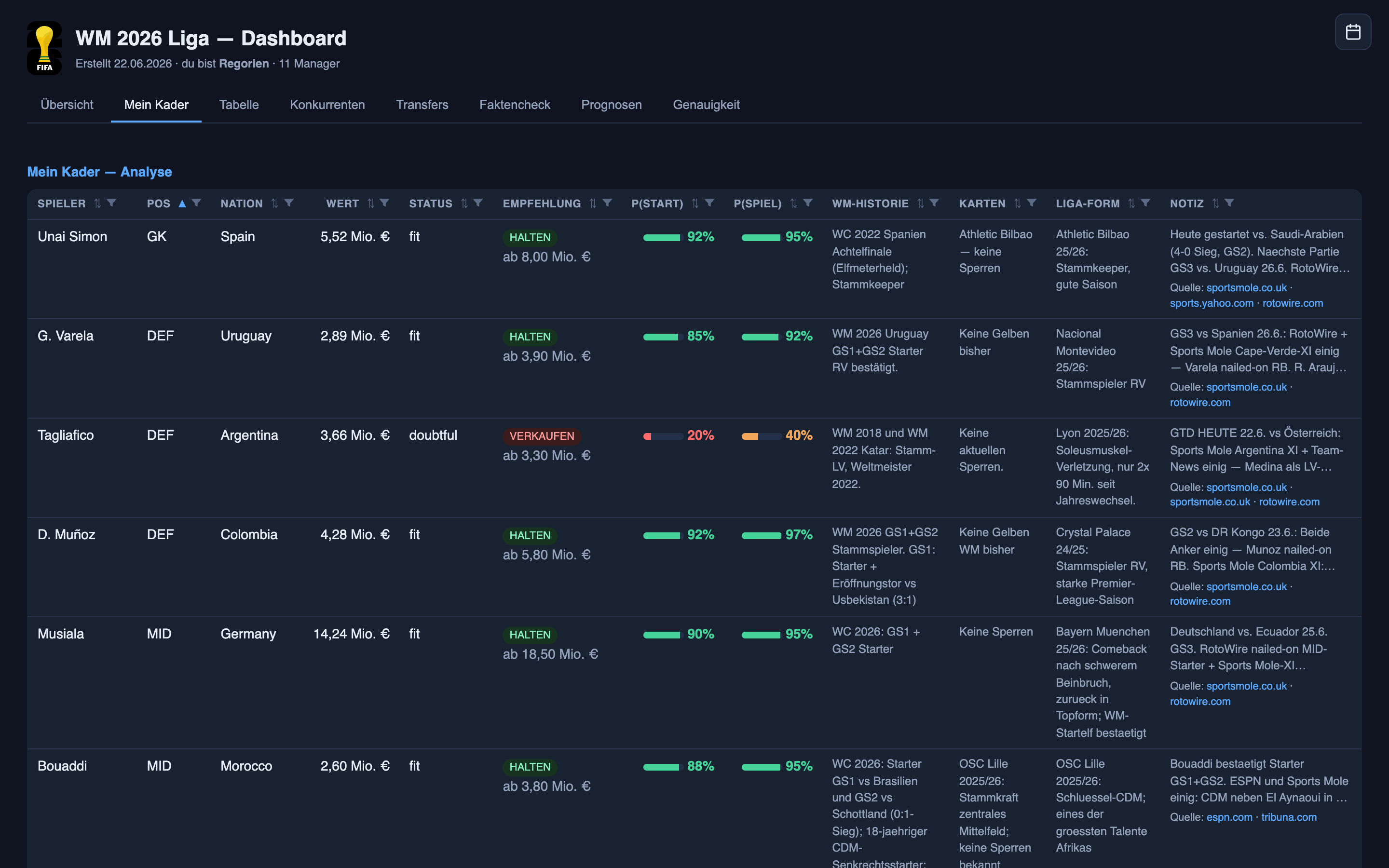
O difícil que ele acertou: Unai Simón. O goleiro da Espanha vinha de uma fase ruim, a imprensa estava cheia de conversa de rodízio, e o treinador não deu sinal claro para nenhum lado — um palpite genuinamente turvo, nada óbvio. O sistema ficou do lado de ele ser titular e manteve essa linha através do barulho. Ele foi titular e jogou os noventa minutos. É o sistema fazendo o que eu mais quero dele: o quadro de fora dizia “talvez”, o sistema disse “ele é titular”, e estava certo. Uma leitura de uma situação turva, não um fato copiado de uma escalação — e é o tipo de coisa que o lado do quem-joga acerta na maioria das vezes.
O erro que me custou: Crepeau. Vendi o goleiro do Canadá porque o sistema o tinha em só 40% de chance de ser titular — uma inclinação para o banco. Ele jogou os noventa minutos e fez quatro pontos que eu não tinha mais. Uma perda real, e que posso pôr na conta do modelo: 40% não era “não”, era uma cara-ou-coroa vestida de inclinação, e eu tratei como uma decisão.
O outro lado da mesma moeda: Asare. Eu comprei o goleiro de Gana porque o sistema o pôs em 55% — uma inclinação para ser titular. Ele não foi titular; só entrou quando o goleiro titular de Gana, Ati Zigi, saiu machucado. Duas transferências, direções opostas, mesma causa raiz: na faixa de 40–60%, a confiança do sistema é pouco melhor do que um cara-ou-coroa, e eu fico confundindo “pouco” com “provavelmente”.
O confiante que mesmo assim errou: Angulo. O atacante do Equador — herói da parte um — estava em 78% de chance de ser titular. Não foi; entrou do banco aos 56 minutos. É um palpite na faixa de 60–80%, justamente a que o gráfico de calibração mostra correndo cerca de oito pontos quente. Então o causo e os dados concordam: quando esse sistema diz “bem provável”, desconte um pouco.
E então as cartas fora do baralho que nenhum modelo poderia ter lido: um goleiro reserva da Austrália que tínhamos em 2% jogou os noventa minutos inteiros porque o treinador deixou o titular no banco na manhã do jogo; um meio-campista colombiano em 3% jogou oitenta minutos. Puro capricho de treinador, decidido num vestiário, impossível de saber de fora. Esses são os erros irredutíveis — e o honesto é contá-los, não explicá-los para longe.
A armadilha mais profunda: prever quem joga não é prever como vão se sair
Aqui está o que mais me ensinou. Valery, um zagueiro da Tunísia, foi titular e jogou 72 minutos — o sistema o tinha como provável de entrar em campo, e a leitura da escalação estava certa. O problema é que a Tunísia foi desmontada por 5–1, e um zagueiro do lado errado disso saiu com −2 pontos. Escalei um jogador que o sistema corretamente disse que jogaria, e perdi pontos mesmo assim.
Essa lacuna importa em todo lugar. “Essa pessoa vai estar no turno” e “esse turno vai correr bem” são perguntas diferentes, e um sistema bom na primeira pode ser inútil na segunda se você as confundir. O conserto não é um modelo de escalação melhor — é adicionar a segunda pergunta de forma explícita: dado quem está jogando e contra quem, qual é o resultado esperado, e quão feio pode ficar? Um titular num time prestes a ser atropelado é uma armadilha que a previsão de escalação não enxerga sozinha.
A má notícia: acertar o placar é a metade fraca — e em parte sempre será
O que nos leva aos placares, onde o sistema foi, claramente, ruim.
Nas 24 partidas de abertura ele acertou o vencedor 46% das vezes — errado mais da metade do tempo — e o placar exato só 8% (duas partidas de 24). Um chute às cegas entre vitória, empate e derrota cai perto de um terço, então o modelo não está escolhendo ao acaso; ele só não chama bem.
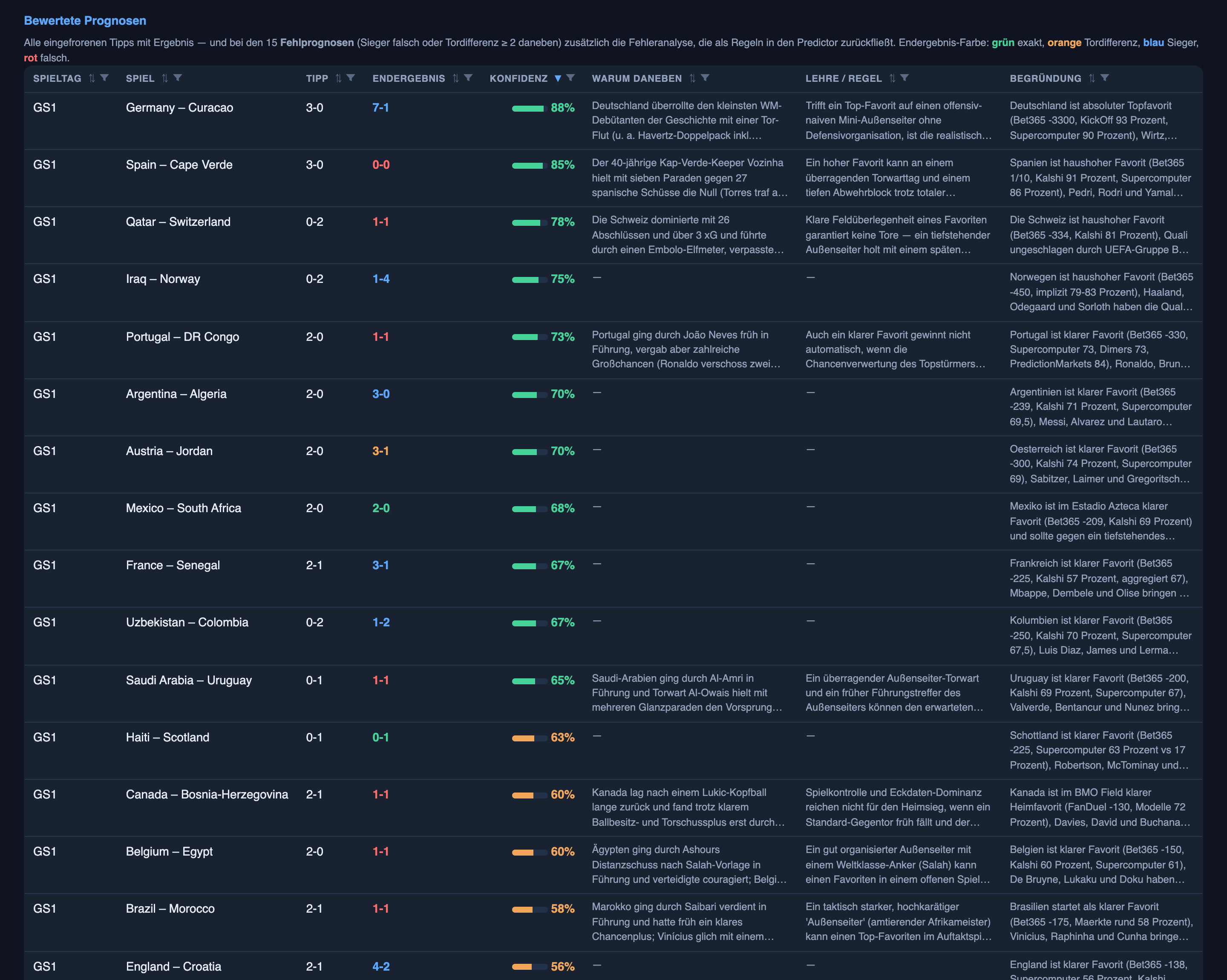
Três partidas contam a história inteira.
Espanha 0–0 Cabo Verde — a genuinamente imprevisível. O sistema apostou na Espanha vencendo por 3–0 com 85% de confiança. A Espanha é um gigante; Cabo Verde era estreante em Copas; os mercados de apostas concordavam; tudo apontava para um lado. Terminou 0–0. Não há lição aqui exceto humildade: às vezes um favorito pesado esbarra numa defesa fechada e num goleiro tendo a tarde da vida dele, e nenhuma quantidade de inteligência prevê um 0–0 específico. O conserto honesto não é “preveja melhor” — é “não tenha 85% de certeza de nada num único jogo de poucos gols”.
Turquia 0–2 para a Austrália — a que, discutivelmente, deveríamos ter inclinado diferente. Aqui o sistema na verdade favoreceu a Turquia, apostando nela para vencer por 2–1 com 55%. Ela perdeu por 0–2 e jogou mal. Dava para saber? Em parte — a forma recente de um time e a profundidade do elenco são legíveis, e 55% já era quase um cara-ou-coroa, então o modelo não estava confiante, só levemente errado. Este é o meio-termo: não imprevisível como a Espanha, não um bug sistemático — só uma inclinação que provavelmente deveria ter ido para o outro lado.
Tunísia 1–5 para a Suécia — a goleada que subestimamos. O sistema apostou numa vitória apertada da Suécia, 1–0. A Suécia ganhou de 5–1. Acertou o vencedor e errou a escala completamente — e esse mesmo ponto cego é o motivo de os pontos negativos de Valery terem me pegado de surpresa. É o erro oposto ao da Espanha: lá, fomos ousados demais com um favorito que empatou; aqui, tímidos demais num confronto desigual que virou massacre.
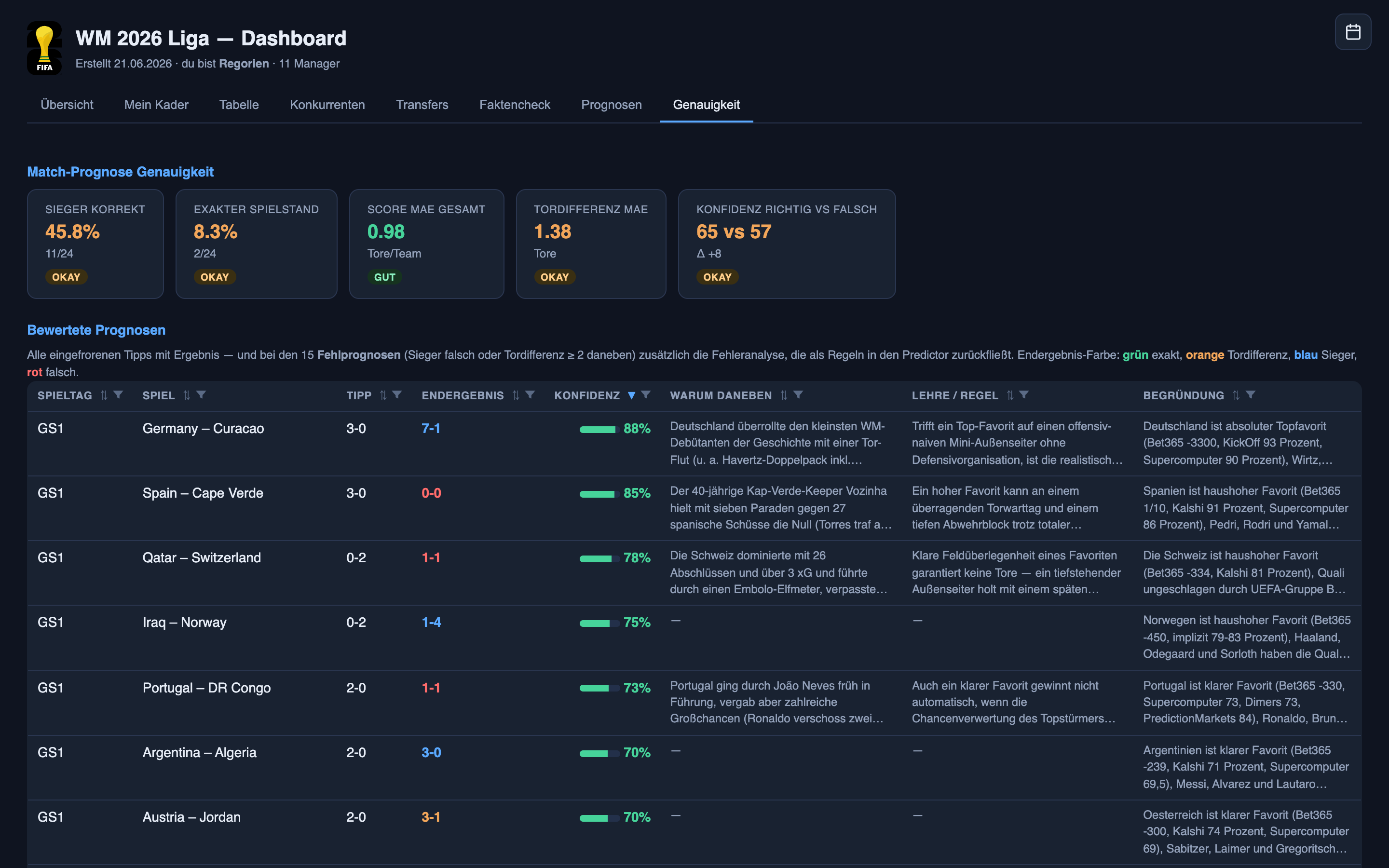
Juntando tudo, esses três são o diagnóstico de verdade. O sistema não é simplesmente “confiante demais” ou “cauteloso demais” — ele está errado sobre como os placares de futebol se comportam. Gols são raros, uma partida inteira pode virar em um só, e eventos raros são dominados por uma sorte que nenhum modelo consegue remover porque ela ainda não aconteceu. Há sinal real para se apoiar — os mercados de apostas, o guia de forma, o melhor time vencendo na maioria das vezes, e o sistema usa tudo isso — mas ele fica soterrado por baixo dessa aleatoriedade. A coisa mais importante de entender sobre previsão, no futebol ou nos negócios: algumas perguntas têm respostas esperando para serem encontradas, e algumas estão genuinamente nas mãos do acaso. Um bom sistema tem que saber qual é qual — alto onde há sinal, humilde onde só há ruído. Esta semana, o meu não foi humilde o suficiente: sua confiança mal separava os acertos dos erros (cerca de 65% de certeza quando certo, 57% quando errado). Fechar essa lacuna importa mais do que correr atrás de uns poucos placares corretos — e é uma das primeiras coisas que mudei para a segunda rodada.
Como as previsões são feitas — e como o sistema de fato aprende
Vale puxar a cortina, porque a parte do “como ele aprende” é onde isto deixa de ser sobre futebol.
Antes de cada rodada, um agente pesquisador vai nação por nação e monta o quadro — escalações prováveis, lesões, forma, quem está rodando. Um agente preditor transforma isso num placar e numa confiança. Nada disso são regras fixas que escrevi meses atrás; os agentes leem o mundo atual a cada vez e raciocinam do zero. Essa é a diferença entre automatizar um relatório e contratar um analista que por acaso é feito de software.
Mas raciocinar do zero não é o mesmo que aprender. Então esta semana adicionei uma peça nova: um agente avaliador — imagine um inspetor de controle de qualidade que entra depois do turno, vê o que a linha de produção errou e anota os padrões. Depois das partidas, ele puxa os resultados e as escalações reais, pontua os dois e — o passo-chave — destila os erros numa lista curta de lições em linguagem simples. Não um despejo de dados; um punhado de padrões, sem duplicatas, cada um com evidência e uma mudança concreta de regra. Algumas das lições que ele mesmo escreveu esta semana:
“Favoritos contra azarões fechados atrás com um bom goleiro foram sistematicamente superestimados — domínio territorial não virou gols; o azarão arrancou um empate numa bola parada no fim.” Evidência: Espanha–Cabo Verde, Catar–Suíça, Bélgica–Egito.
“Goleadas contra fraquinhos ofensivamente ingênuos foram subestimadas, porque baixa confiança foi erroneamente igualada a poucos gols. Desacople confiança do placar.” Evidência: Alemanha, apostada em 3–0, ganhou de 7–1; Suécia 1–0 → 5–1.
“Jogos da fase de grupos da Copa do Mundo são em campo NEUTRO — não há vantagem de mando, exceto para os anfitriões. O time listado em primeiro recebeu erroneamente uma vantagem de casa.”
É o ciclo se fechando. Antes da próxima rodada, o preditor lê seu arquivo de lições e o pesquisador lê o seu, e ambos se ajustam. O lado das escalações até escreveu para si mesmo esta nota — “a faixa de 20–40% corre quente; a faixa de 80–100% está bem calibrada, confie nela” — o sistema diagnosticando o próprio ponto fraco, por escrito, para a próxima vez.
Agora o limite honesto, porque é aqui que o hype costuma tomar conta. Quando digo que o sistema “aprende”, eu não quero dizer que ele recabeia algum cérebro gigante da noite para o dia. Há dois jeitos de uma IA mudar. Um é caro e lento — retreinar o próprio modelo, uma caixa-preta no fim. O outro é o que estou fazendo: as lições ficam num arquivo de texto simples que o modelo lê no início de cada execução, como um contratado afiado que mantém um caderninho de “coisas que errei e o que vou fazer diferente” e o revisa antes de cada tarefa. É barato, é instantâneo e — a parte que importa para um negócio — é inspecionável: posso ler cada lição, discordar dela, apagar uma ruim. E ruins acontecem — um avaliador pode escrever uma lição que soa plausível mas é, na verdade, errada, que é exatamente o motivo de um humano lê-las antes de alimentarem a próxima rodada. Um sistema cujo aprendizado você pode ler e revogar é um que você consegue rodar dentro de uma empresa. Uma caixa-preta que “simplesmente fica melhor” é uma que você nunca vai passar pelo seu auditor.
E há um teto. O ciclo consegue corrigir vieses — a vantagem de mando fantasma, o 1–1 reflexo, a faixa do meio confiante demais. Esses são reais, sistemáticos, corrigíveis, e espero que encolham na próxima rodada. O que ele não consegue corrigir é a aleatoriedade — a sorte irredutível num jogo de poucos gols. Nenhum caderninho torna uma zebra 0–0 previsível. Então a meta inteligente não é “prever placares melhor”. É “saber quais palpites merecem confiança e quais são honestamente cara-ou-coroa” — e aí o ciclo genuinamente ajuda.
Tire o futebol da equação
Leia as últimas seções de novo, mas apague a palavra “futebol”.
Um sistema faz previsões. Você as pontua com honestidade — e a primeira coisa que descobre é que a sua própria pontuação era pouco confiável: avaliando entradas vencidas, confundindo dois registros da mesma entidade, carregando uma suposição escondida do contexto errado. Então você conserta o pontuador com checagens baratas, baseadas em regras, antes de confiar num único número. Aí suas previsões se dividem limpas em duas: as que são sobre coisas cognoscíveis são afiadas, e as que são sobre coisas genuinamente incertas são medíocres — e a vitória de verdade é um sistema honesto o suficiente para te dizer qual é qual. E você aprende não retreinando uma caixa-preta, mas mantendo um caderninho legível de lições que um humano pode auditar.
Vamos concretizar. Se alguém se oferecesse para prever a sua receita exata do próximo trimestre, até o euro, você teria razão de desconfiar — isso é um problema Espanha-contra-Cabo-Verde, quase todo ruído. Mas “quais dos nossos clientes estão quietamente derivando para nos deixar”, “o preço de qual fornecedor subiu mais rápido do que o mercado”, “qual nota fiscal desta semana não se parece com as outras” — esses são problemas do tipo quem-vai-ser-titular: a resposta já está nos seus próprios dados, alguma coisa só precisa lê-la toda manhã, pontuar a si mesma com honestidade e te dizer o quão certa está. E — a lição de Valery — não pare em “quem vai estar no turno”; pergunte “e como esse turno provavelmente vai correr”, porque as duas são perguntas diferentes. Isso é previsão de demanda, detecção de churn, monitoramento de risco de fornecedor, detecção de anomalias — e o mesmo formato de sistema funciona igualmente bem apontado para os seus próprios dados, atrás do seu próprio firewall, não para a web aberta. Os jogadores de futebol só deixam o placar público e o risco baixo o suficiente para mostrar a coisa inteira, erros e tudo.
Tá bom. De volta ao jogo.
O que mudei para a segunda rodada — e o que espero
Quase tudo de útil esta semana veio dos erros, não dos acertos. As lições não foram só anotadas; elas realimentaram dois conjuntos concretos de mudanças antes da próxima rodada começar — um para os palpites de escalação, um para os placares. Para registro, aqui está o que de fato está diferente, e o que espero de cada um.
Os palpites de escalação (quem vai jogar) — principalmente consertando calibração e pontos cegos:
- Puxar para baixo o meio confiante demais. A faixa de 20–40% corria cerca de 18 pontos quente, então ela é cortada; as faixas de 40–60% e 60–80% estavam mais ou menos 8 pontos altas, então são aparadas. A faixa de 80–100% é deixada em paz — já era honesta.
- Parar de tratar só os nomes famosos como garantidos. A rodada de abertura estava cheia de titulares sem glamour de nações menores que tínhamos estacionado em 2–15% e que jogaram mesmo assim — então o pesquisador agora credita um titular estabelecido independentemente do perfil, e trata um nome grande que perdeu seu lugar com mais desconfiança (fama não é a hierarquia atual).
- Sinalizar a zebra da estreia. Um treinador poupando um titular em forma — o palpite que me custou com aquele goleiro reserva — agora é um risco conhecido, não uma surpresa.
- Manter as entradas frescas. A trava contra previsões vencidas mais uma atualização completa na manhã de cada jogo significa que não há mais fantasmas de três semanas na nota.
O que espero: a calibração aperta, especialmente aquela faixa do meio. A manchete de 84% pode não saltar — mas fica mais honesta, que é o ponto.
Os palpites de placar — aqui as lições são sobre como os gols de fato se comportam:
- Desacoplar confiança do placar. Baixa confiança parou de significar “poucos gols”, então um confronto desigual genuíno pode ser apostado como a goleada que é, não um educado 3–0 (Alemanha 7–1, Suécia 5–1 são como aquele erro se pareceu).
- Proteger contra o favorito pesado. Contra um azarão fechado atrás com um bom goleiro, espere o empate muito mais vezes — e pare de ter 85% de certeza de um 3–0 (Espanha 0–0; o monte de 1–1).
- Quebrar o 1–1 reflexo. Num cara-ou-coroa em que um lado domina a bola, incline para uma vitória apertada desse lado em vez de dividir a diferença.
- Sem vantagem de mando num torneio neutro (fora os anfitriões).
- Alargar a confiança onde é um cara-ou-coroa. Diga “esse aqui é cara-ou-coroa” em voz alta em vez de fingir precisão — aquela lacuna de 65 contra 57 é a que precisa ser fechada.
O que espero: a precisão de vencedor deve subir dos 46%. Ainda não estou prometendo bons placares — a aleatoriedade é real — mas a confiança deveria, ao menos, começar a dizer a verdade sobre si mesma.
A terceira mudança é a silenciosa: a própria avaliação agora é datada, codificada por cor, autocorretiva e pública, então nada acima pode me adular no escuro.
O que arma o teste honesto. Depois da segunda rodada eu vou publicar este mesmo boletim de novo — e você vai ver, em público, se essas mudanças de fato moveram os números ou só soaram bem no papel. Isso, no fim, é a única forma de distinguir um sistema que aprende de um que apenas relata. A coisa toda fica aberta, pontuada contra a realidade, atualizada depois de cada rodada — você pode ver ela melhorar, ou não, sem ter que acreditar na minha palavra.
Um último pensamento, e aí eu te deixo ir. A coisa mais útil desta semana não veio da IA sendo inteligente. Veio de ser forçado a responder duas perguntas entediantes com honestidade: posso confiar no meu próprio placar, e quais dos meus palpites de fato merecem confiança? Essas perguntas não se importam se o assunto é futebol, frete ou notas fiscais — e, na minha experiência, a atualização para um modelo mais chique é perseguida muito antes de qualquer uma das duas ser respondida. Se o seu trabalho roda sobre previsões e você nunca confiou de verdade no painel que as avalia, você já sabe qual é o problema mais interessante para mastigar — e o primeiro passo honesto é simplesmente ver a próxima rodada aterrissar na página pública antes de tomar qualquer coisa que eu disse como fé. Se em algum lugar aqui você viu o seu próprio mundo em vez de um campo de futebol, bem — você sabe onde me encontrar.