cat artículos/ai-predictions-graded-matchday-1.mdx
Comunio World Cup 2026 · Parte 2Predicciones, evaluadas con honestidad: buenas para acertar quién juega, flojas para acertar el marcador
Un equipo de agentes de IA jugando una liga fantasy del Mundial 2026 evalúa en público sus predicciones tras la primera jornada: acierta quién juega, falla el marcador.
22 jun 2026 · por Daniel Deusing · ~24 min de lectura #ai #agents #football
En el primer artículo escribí sobre un equipo de agentes de IA que construí para jugar una liga fantasy del Mundial 2026, e hice una promesa: volvería una vez disputados los partidos y evaluaría las predicciones en público — de verdad, mostrando los fallos, no solo los aciertos. La primera ronda de partidos de grupo ya está. Aquí está el boletín de notas.
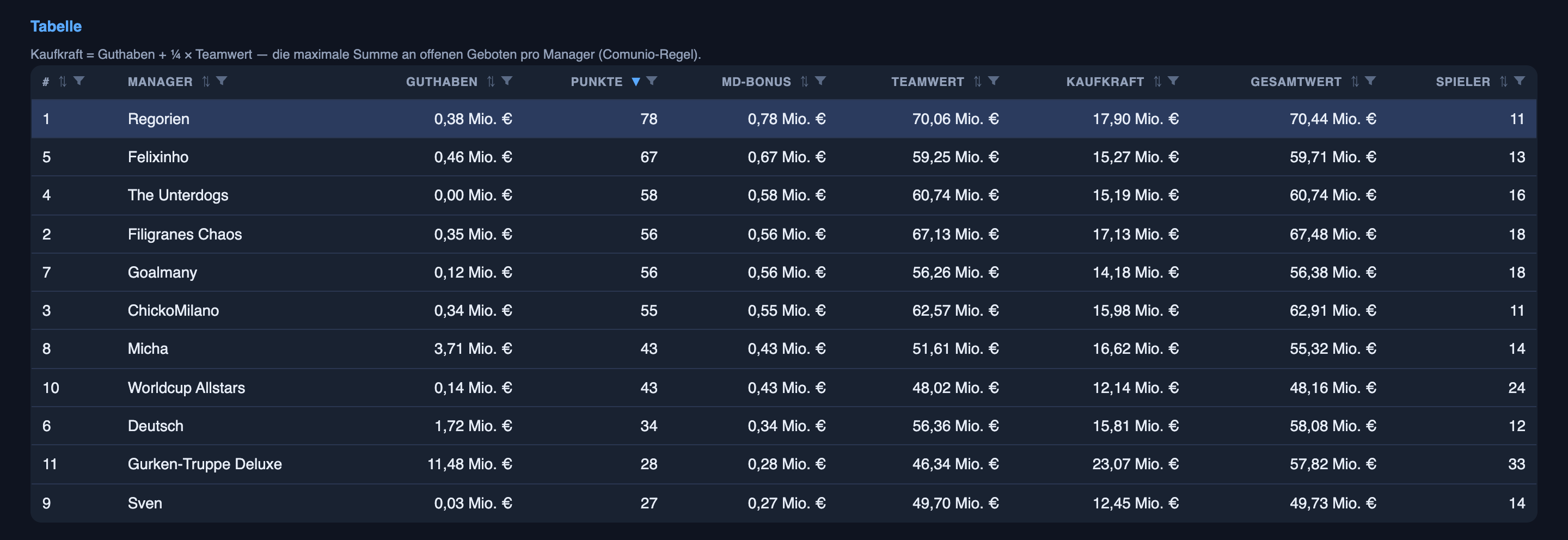
La plantilla en sí va bien — se sitúa cerca de lo más alto de nuestra pequeña liga de amigos tras una jornada. Pero quiero ser honesto sobre el porqué: eso se debe sobre todo a la compraventa de la primera parte, no a las predicciones de los partidos. Las predicciones son una historia distinta, más interesante — y el titular es una división que no esperaba:
La parte vistosa — acertar marcadores — es, por ahora, en la que menos brilla. La parte ingrata — acertar quién va a estar realmente en el once titular — es donde ya es fiable. La razón honesta de la diferencia no es que una lea datos y la otra adivine — ambas se apoyan en datos (noticias del equipo y filtraciones de alineaciones para el once; mercados de apuestas y forma para los marcadores) y ambas implican adivinanza real. La diferencia está en cuánto de la respuesta queda decidido antes del pitido inicial. Quién sale es algo que en su mayoría se decide de antemano, así que una buena información te lleva muy lejos — salvo la ocasional sorpresa del entrenador que no se puede leer desde fuera. Un marcador se decide en su mayoría a lo largo de noventa minutos de caos, así que ni la mejor información hace más que acotarlo; no puede fijarlo. El mismo sistema, dos problemas con cantidades de azar muy distintas metidas dentro — y esa distinción, no el fútbol, es la parte útil.
Pero antes de cualquier nota, una confesión sobre la evaluación en sí — porque ahí está la primera lección de verdad.
Resumen rápido, por si te perdiste la primera parte: estoy en un juego fantasy donde compras y vendes futbolistas reales en una subasta a ciegas — pujas selladas, nadie ve la de los demás, gana el número más alto — y un equipo de agentes de IA hace los deberes diarios. Este artículo trata de la otra promesa que hice allí: que el sistema evaluaría sus propias predicciones contra la realidad, en público, desde la noche en que sonó el primer silbato.
Tuve que arreglar el evaluador antes de poder confiar en él
Esta es la parte que es fácil saltarse. Cuando llegaron los primeros resultados, mi flamante página de precisión arrojó números en los que no podía confiar — no porque las predicciones fueran buenas o malas, sino porque la evaluación tenía errores. Tres de ellos vale la pena nombrarlos, porque cada uno es un fallo que comete cualquier empresa la primera vez que intenta medir un sistema de IA con honestidad.
Evaluaba predicciones caducadas. Uno de mis jugadores, el centrocampista austriaco Laimer, figuraba en la evaluación marcado como “no jugará” al 95% — y luego jugó los noventa minutos completos. El sistema parecía gravemente equivocado. Pero no se equivocaba esta semana: ese 95% era una suposición de hacía tres semanas que nunca se refrescó antes del partido. Estaba evaluando un pronóstico que el sistema prácticamente había olvidado que hizo. Basura entra, nota basura.
No distinguía a dos personas. Tres jugadores — incluido un defensa inglés llamado O’Reilly — fueron marcados como “no jugó” cuando, de hecho, habían sido titulares todo el partido. El motivo es tan aburrido como importante: el jugador en los datos de la alineación en directo y el jugador en mi predicción eran el mismo humano, registrado bajo dos nombres ligeramente distintos, y el sistema los trató como desconocidos. Es un fallo de manual de resolución de entidades.
Daba ventaja de local en un torneo sin partidos en casa. El modelo le concedía sin avisar una ventaja de campo al equipo listado en primer lugar — pero los partidos de grupo del Mundial se juegan en estadios neutrales (salvo los anfitriones). Una pequeña suposición, heredada del fútbol de liga corriente, sesgándolo todo en silencio.
Fíjate en lo que tienen en común: ninguno fue la IA siendo “tonta”. Los agentes hicieron más o menos lo que se les dijo. Los fallos estaban en la medición — la fontanería que decide qué cuenta como acierto. Y esa es la lección que subrayaría para cualquiera que apueste presupuesto real en un proyecto de IA: construir la cosa es la mitad fácil. Construir un baremo en el que puedas confiar de verdad es la mitad difícil, y es la mitad que se salta. Un número que no puedes defender es peor que ningún número, porque te deja confiado y equivocado al mismo tiempo.
Los arreglos fueron en su mayoría aburridos, que es justo el punto. Una guarda contra caducidad — un trozo de código sencillo, sin IA, que descarta cualquier pronóstico no refrescado para la jornada que está evaluando — ahora corre en cada ciclo, y un conjunto fresco de predicciones queda fijado la mañana de cada partido (se acabaron los fantasmas de 21 días). Un creciente mapa de alias — una tabla de equivalencias de nombres — le enseña al sistema que “Nico O’Reilly” y “O’Reilly” son un solo hombre. La regla del terreno neutral ya está escrita. Las alineaciones se contrastan con el artículo de Wikipedia del partido correspondiente — renderizado en servidor, rápido, con el once confirmado y los suplentes un par de horas después del pitido final, y cada caso atípico citando su fuente. Y los resultados ahora reciben un código honesto de cuatro colores, que verás más abajo. El principio que subyace a todo esto: usar la herramienta cara e inteligente (la IA) solo donde de verdad hace falta criterio, y envolverla en código barato, aburrido e indestructible allí donde importa una garantía.
La buena noticia: quién jugará es en su mayoría predecible — y lo leemos bien
Ahora, las notas. Empecemos por lo que funcionó, porque me sorprendió lo bien que funcionó.
Cada día, para cada jugador, el sistema produce un número que llama p_start. Luego ocurre el partido, y comprobamos.
La forma correcta de juzgar una puntuación de confianza no es “¿acertó?”. Es calibración.
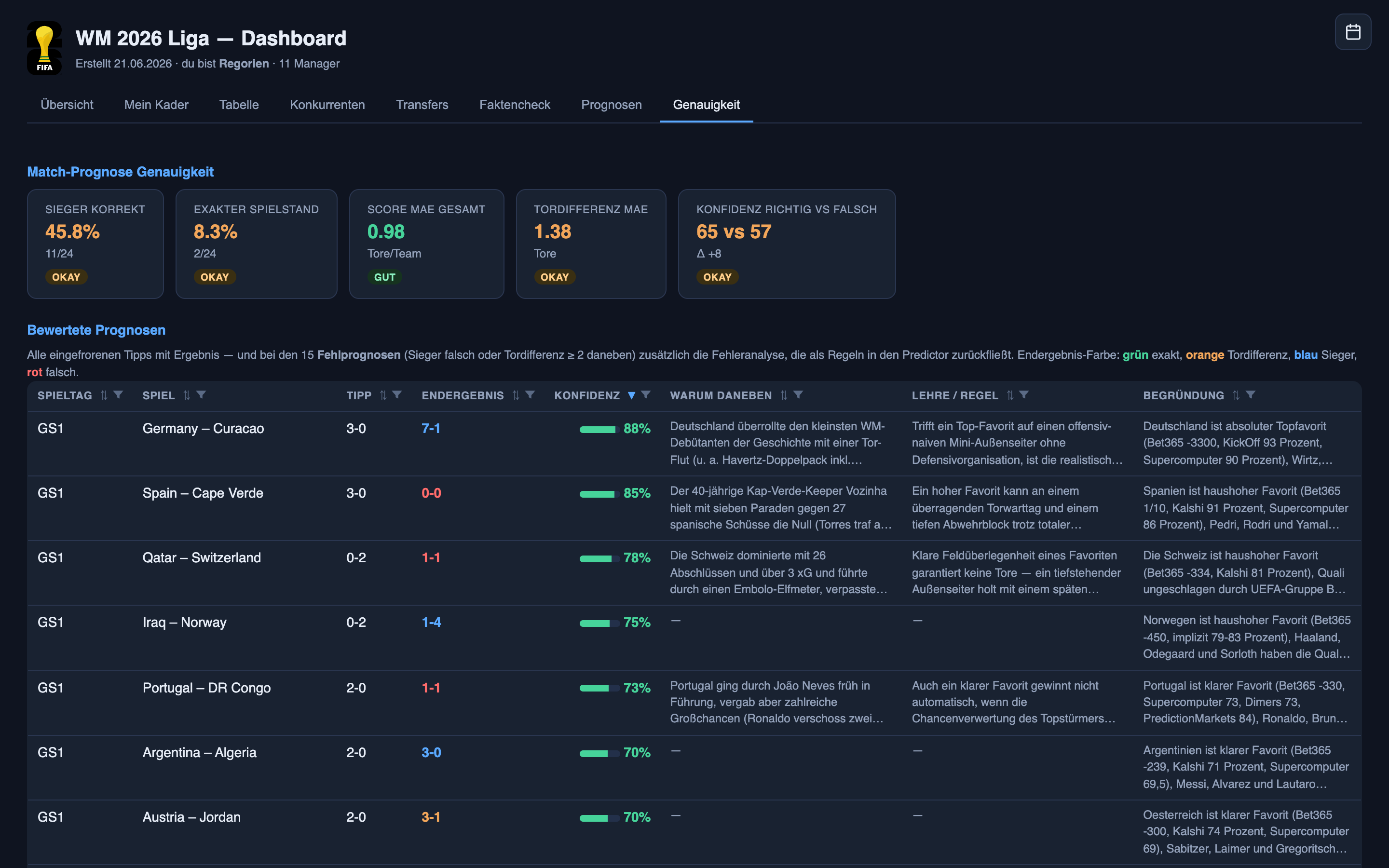
Contra ese listón, el sistema lo hizo bien. En 172 predicciones de titularidad en la jornada inaugural (descartadas las caducadas), acertó el 84% de las veces — pero la forma importa más que el titular:
- Cuando dijo que un jugador tenía un 0–20% de probabilidad de ser titular (71 predicciones), fueron titulares alrededor del 13% de las veces. Casi clavado en los casos improbables.
- Cuando dijo 80–100% (44 predicciones), fueron titulares el 91% de las veces. Cuando este sistema está seguro, puedes creerle.
- El punto débil fue el barro del medio. En la banda del 20–40% (apenas 24 predicciones) implicaba más o menos una de cada tres, pero esos jugadores fueron titulares solo alrededor de una de cada ocho veces — demasiado confiado, sin duda.

Una salvedad justa: esto es una sola jornada, y algunas bandas contienen solo un par de docenas de predicciones, así que léelo como una señal a vigilar, no como un veredicto grabado en piedra. Pero ¿por qué es esta la mitad más estable? Porque quién sale es en gran medida predecible de antemano: noticias del equipo, una rueda de prensa, las costumbres de un entrenador, un parte de lesiones. La mayor parte del trabajo es lectura disciplinada — reunir lo que ya es público, más rápido y de forma más consistente de lo que yo lo haría a mano — y solo una porción es adivinanza genuina: las rotaciones, el entrenador que da una sorpresa que ninguna lectura de alineación podría pillar. Esa mezcla es exactamente lo que muestra la calibración: la lectura es la razón de que las bandas seguras acierten, la adivinanza es la razón de que la banda del medio tambalee.
Lo que acertó y lo que falló con mis propios jugadores
La calibración abstracta es una cosa. Esto es lo que realmente significó para jugadores que tuve, con los que gané y con los que perdí — el registro honesto. Cada predicción vive en la misma pantalla diaria: cada jugador con una probabilidad de titularidad, una probabilidad de jugar, un veredicto de mantener-o-vender, y una nota que enlaza sus fuentes.
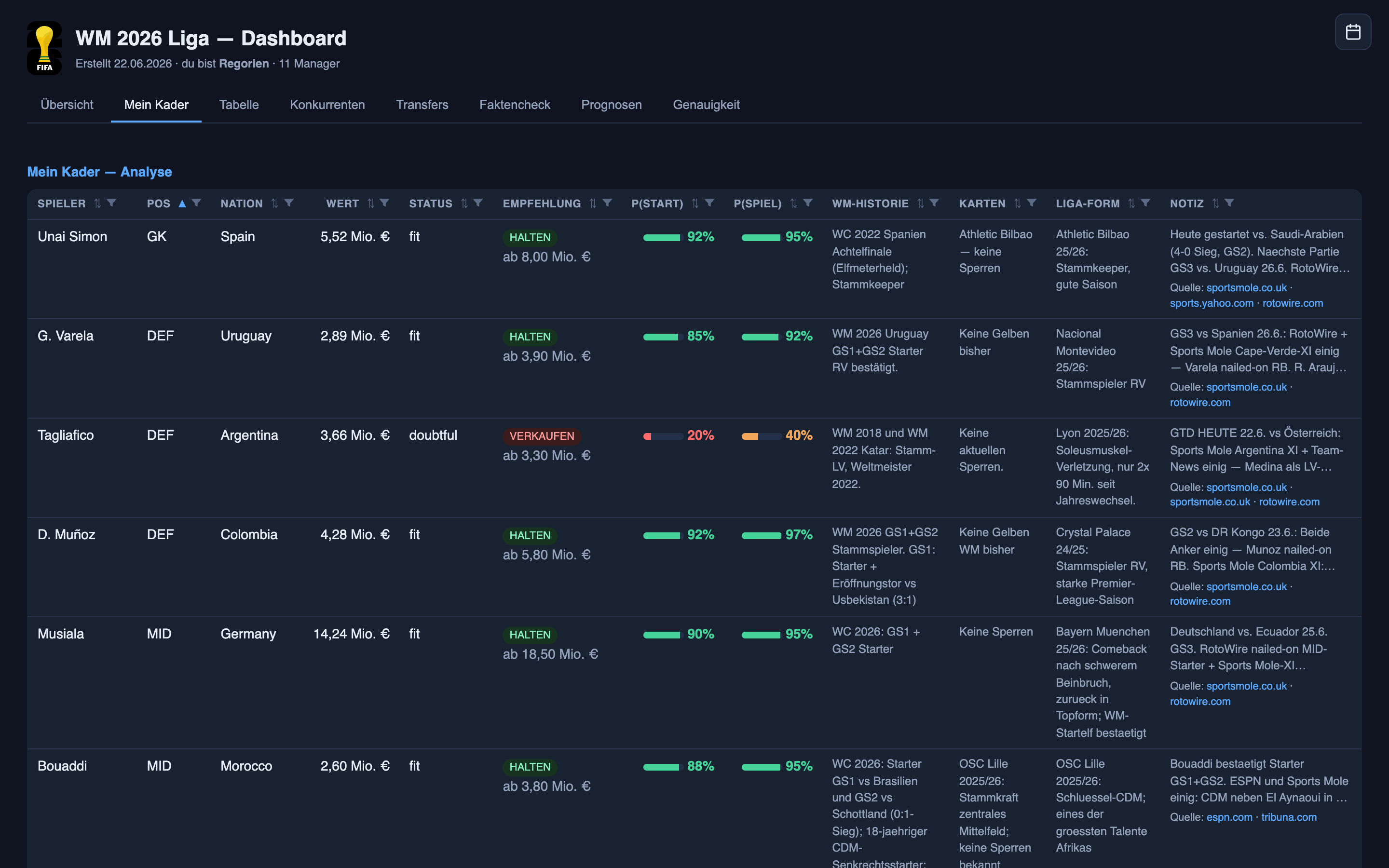
La difícil que acertó: Unai Simón. El portero de España llegaba tras una mala racha, la prensa estaba llena de rumores de rotación, y el entrenador no dio palabra clara en ningún sentido — una predicción genuinamente turbia, no un regalo. El sistema se mantuvo del lado de que sería titular y aguantó esa línea entre el ruido. Fue titular y jugó los noventa. Eso es el sistema haciendo lo que más quiero de él: el panorama desde fuera decía “quizá”, el sistema decía “es titular”, y acertó. Una lectura de una situación turbia, no un dato copiado de una hoja de alineación — y es del tipo que la parte de quién-juega acierta más a menudo que no.
El fallo que me costó: Crepeau. Vendí al portero de Canadá porque el sistema le daba solo un 40% de ser titular — una inclinación hacia el banquillo. Fue titular los noventa minutos y marcó cuatro puntos que ya no tenía. Una pérdida real, y una que puedo cargarle al modelo: el 40% no era un “no”, era un cara o cruz disfrazado de inclinación, y lo traté como una decisión.
La otra cara de la misma moneda: Asare. Compré al portero de Ghana porque el sistema lo ponía en un 55% — una inclinación hacia ser titular. No fue titular; solo entró cuando el portero titular de Ghana, Ati Zigi, salió lesionado. Dos fichajes, en direcciones opuestas, con la misma causa de raíz: en la banda del 40–60%, la confianza del sistema apenas es mejor que un sorteo, y yo sigo confundiendo “apenas” con “probablemente”.
El seguro que aun así falló: Angulo. El delantero de Ecuador — un héroe de la primera parte — tenía un 78% de ser titular. No lo fue; entró desde el banquillo en el minuto 56. Esa es una predicción en la banda del 60–80%, la que el gráfico de calibración muestra yendo unos ocho puntos caliente. Así que la anécdota y los datos coinciden: cuando este sistema dice “bastante probable”, quítale un poco.
Y luego las bolas con efecto que ningún modelo podría haber leído: un portero suplente de Australia que teníamos al 2% jugó los noventa completos porque el entrenador sentó a su titular la mañana del partido; un centrocampista colombiano al 3% jugó ochenta minutos. Puro capricho del entrenador, decidido en un vestuario, imposible de saber desde fuera. Esos son los fallos irreducibles — y lo honesto es contarlos, no explicarlos con excusas.
La trampa más profunda: predecir quién juega no es predecir cómo le irá
Esta es la que más me enseñó. Valery, un defensa de Túnez, fue titular y jugó 72 minutos — el sistema lo daba como probable participante, y la lectura de la alineación fue correcta. El problema es que a Túnez lo desarmaron 5–1, y un defensa en el lado equivocado de eso se fue con −2 puntos. Elegí a un jugador que el sistema, con razón, dijo que jugaría, y aun así perdí puntos.
Esa brecha importa en todas partes. “¿Estará esta persona de turno?” y “¿irá bien ese turno?” son preguntas distintas, y un sistema bueno en la primera puede ser inútil en la segunda si las confundes. El arreglo no es un mejor modelo de alineaciones — es añadir la segunda pregunta de forma explícita: dado quién juega y contra quién juega, ¿cuál es el resultado esperado, y cuán mal puede salir? Un titular en un equipo a punto de ser arrollado es una trampa que el pronóstico de alineación no puede ver por sí solo.
La mala noticia: acertar el marcador es la mitad débil — y en parte siempre lo será
Lo que nos lleva a los marcadores, donde el sistema fue, sin más, flojo.
En los 24 partidos de la jornada inaugural acertó el ganador el 46% de las veces — falló más de la mitad — y el marcador exacto apenas el 8% (dos partidos de 24). Una adivinanza a ciegas entre victoria, empate y derrota ronda un tercio, así que el modelo no acierta al azar; simplemente no los está acertando bien.
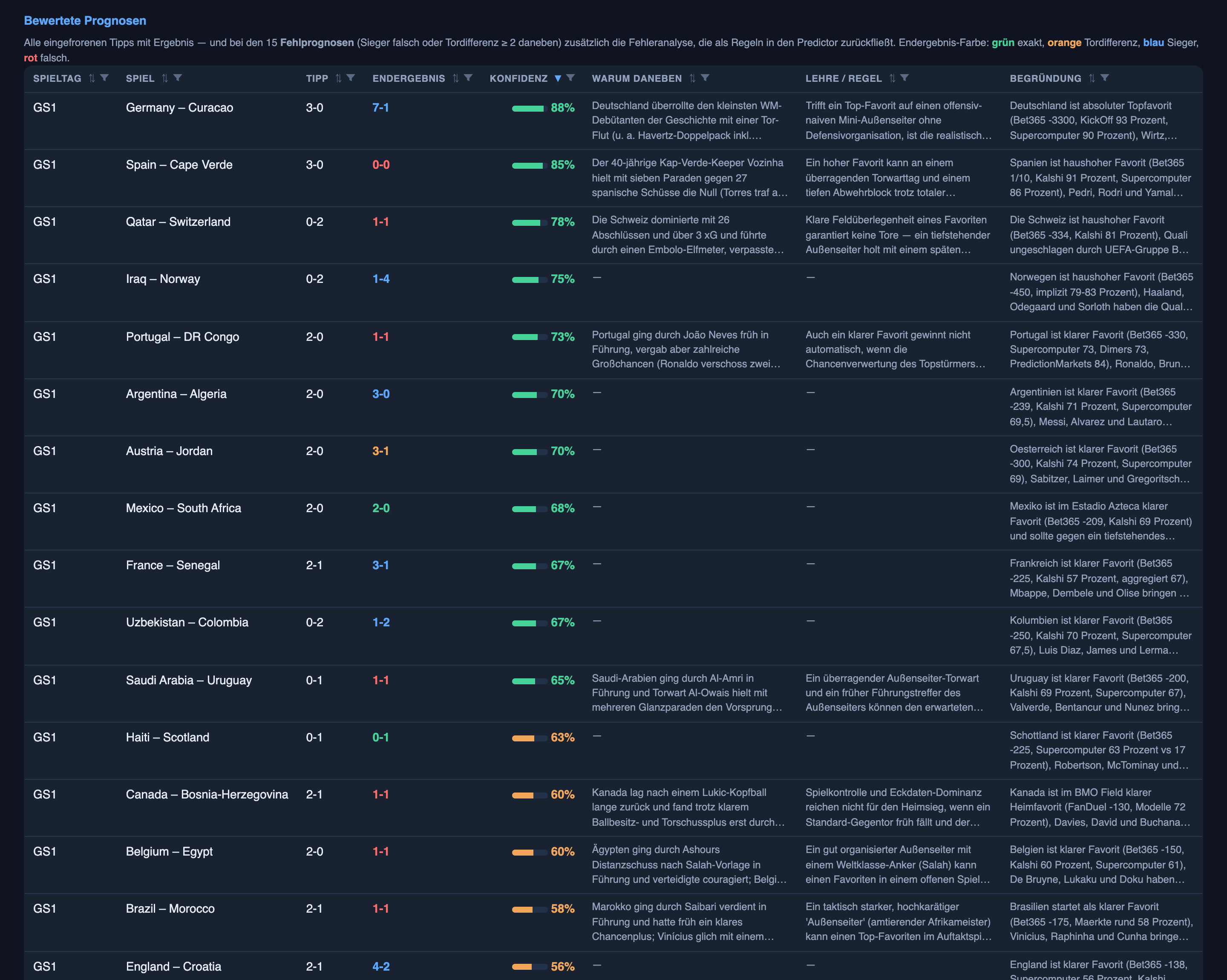
Tres partidos cuentan toda la historia.
España 0–0 Cabo Verde — el genuinamente imprevisible. El sistema pronosticó victoria de España 3–0 con un 85% de confianza. España es un gigante; Cabo Verde debutaba en un Mundial; los mercados de apuestas coincidían; todo apuntaba en una dirección. Acabó 0–0. Aquí no hay más lección que la humildad: a veces un favorito claro se topa con una defensa replegada y un portero teniendo la tarde de su vida, y ninguna cantidad de inteligencia prevé un 0–0 concreto. El arreglo honesto no es “predícelo mejor” — es “no estés 85% seguro de nada en un único partido de pocos goles”.
Turquía 0–2 ante Australia — el que probablemente deberíamos haber inclinado de otra forma. Aquí el sistema en realidad favoreció a Turquía, pronosticando victoria 2–1 con un 55%. Perdieron 0–2 y dieron mala imagen. ¿Podríamos haberlo sabido? En parte — la forma reciente y la profundidad de plantilla de un equipo se pueden leer, y el 55% ya era casi un cara o cruz, así que el modelo no estaba seguro tanto como levemente equivocado. Este es el terreno intermedio: no imprevisible como España, no un error sistemático — solo una inclinación que probablemente debería haber ido al revés.
Túnez 1–5 ante Suecia — la goleada que infravaloramos. El sistema pronosticó una victoria ajustada de Suecia, 1–0. Suecia ganó 5–1. Acertó el ganador y se equivocó por completo en la escala — y ese mismo punto ciego es la razón de que los puntos negativos de Valery me pillaran por sorpresa. Este es el error opuesto al de España: allí, fuimos demasiado atrevidos con un favorito que empató; aquí, demasiado tímidos con un desajuste que se convirtió en una masacre.
Puestos juntos, esos tres son el diagnóstico real. El sistema no es simplemente “demasiado confiado” o “demasiado cauto” — está equivocado sobre cómo se comportan los goles en el fútbol. Los goles son raros, un partido entero puede girar sobre uno, y los eventos raros están dominados por un azar que ningún modelo puede eliminar porque aún no ha ocurrido. Hay señal real en la que apoyarse — los mercados de apuestas, la guía de forma, el mejor equipo ganando más a menudo que no, y el sistema usa todo ello — pero queda enterrada bajo esa aleatoriedad. Lo más importante que entender sobre la predicción, en el fútbol o en los negocios: algunas preguntas tienen respuestas esperando a ser encontradas, y otras quedan genuinamente al azar. Un buen sistema tiene que saber cuál es cuál — contundente donde hay señal, humilde donde solo hay ruido. Esta semana, el mío no fue lo bastante humilde: su confianza apenas separaba sus aciertos de sus fallos (alrededor de un 65% seguro cuando acertaba, un 57% cuando fallaba). Cerrar esa brecha importa más que perseguir un par de marcadores correctos — y es una de las primeras cosas que he cambiado para la segunda jornada.
Cómo se hacen las predicciones — y cómo aprende realmente el sistema
Vale la pena descorrer el telón, porque la parte de “cómo aprende” es donde esto deja de tratar sobre el fútbol.
Antes de cada jornada, un agente investigador va nación por nación y arma el panorama — alineaciones probables, lesiones, forma, quién rota. Un agente predictor lo convierte en un marcador y una confianza. Nada de ello son reglas codificadas a mano que yo escribí hace meses; los agentes leen el mundo actual cada vez y razonan de nuevo. Esa es la diferencia entre automatizar un informe y contratar a un analista que resulta estar hecho de software.
Pero razonar de nuevo no es lo mismo que aprender. Así que esta semana añadí una pieza nueva: un agente evaluador — imagina a un inspector de control de calidad que entra después del turno, ve qué hizo mal la línea de producción, y redacta los patrones. Tras los partidos, recupera los resultados y alineaciones reales, puntúa ambos, y — el paso clave — destila los fallos en una lista corta de lecciones en lenguaje llano. No un vertido de datos; un puñado de patrones, sin duplicados, cada uno con pruebas y un cambio de regla concreto. Algunas de las lecciones que se escribió a sí mismo esta semana:
“Los favoritos contra rivales replegados con un portero fuerte fueron sistemáticamente sobrevalorados — el dominio territorial no se tradujo en goles; el rival arañó un empate con una jugada a balón parado tardía.” Pruebas: España–Cabo Verde, Catar–Suiza, Bélgica–Egipto.
“Las goleadas contra equipos ofensivamente ingenuos fueron infravaloradas, porque la baja confianza se equiparó erróneamente con pocos goles. Desacoplar confianza de marcador.” Pruebas: Alemania, pronosticada 3–0, ganó 7–1; Suecia 1–0 → 5–1.
“Los partidos de grupo del Mundial son en terreno NEUTRAL — no hay ventaja de local salvo los anfitriones. Al equipo listado en primer lugar se le dio erróneamente ventaja de campo.”
Eso es el bucle cerrándose. Antes de la siguiente jornada, el predictor lee su archivo de lecciones y el investigador lee el suyo, y ambos se ajustan. La parte de las alineaciones incluso se escribió esta nota — “la banda del 20–40% va caliente; la banda del 80–100% está bien calibrada, confía en ella” — el sistema diagnosticando su propio punto débil, por escrito, para la próxima vez.
Ahora el límite honesto, porque aquí es donde el bombo suele tomar el mando. Cuando digo que el sistema “aprende”, no quiero decir que recablee algún cerebro gigante de la noche a la mañana. Hay dos maneras de que una IA cambie. Una es cara y lenta — reentrenar el modelo en sí, una caja negra al final. La otra es lo que estoy haciendo yo: las lecciones viven en un archivo de texto plano que el modelo lee al inicio de cada ejecución, como un fichaje espabilado que lleva un cuaderno de “cosas que hice mal y qué haré distinto” y lo repasa antes de cada tarea. Es barato, es instantáneo y — la parte que importa para un negocio — es inspeccionable: puedo leer cada lección, discutirla, borrar una mala. Y las malas ocurren — un evaluador puede escribir una lección que suena plausible pero en realidad está equivocada, que es exactamente la razón por la que un humano las lee antes de que alimenten la siguiente ronda. Un sistema cuyo aprendizaje puedes leer y anular es uno que puedes hacer funcionar dentro de una empresa. Una caja negra que “simplemente mejora” es una que nunca pasará tu auditoría.
Y hay un techo. El bucle puede arreglar sesgos — la ventaja de local fantasma, el 1–1 reflejo, la banda media demasiado confiada. Esos son reales, sistemáticos, corregibles, y espero que encojan la próxima jornada. Lo que no puede arreglar es la aleatoriedad — la suerte irreducible en un partido de pocos goles. Ningún cuaderno hace previsible un 0–0 sorpresa. Así que el objetivo inteligente no es “predecir mejor los marcadores”. Es “saber qué predicciones merecen confianza y cuáles son honestamente un cara o cruz” — y ahí, el bucle ayuda de verdad.
Quítale el fútbol
Vuelve a leer las últimas secciones, pero borra la palabra “fútbol”.
Un sistema hace pronósticos. Los puntúas con honestidad — y lo primero que descubres es que tu propia puntuación no era fiable: evaluabas entradas caducadas, confundías dos registros de la misma entidad, arrastrabas una suposición oculta del contexto equivocado. Así que arreglas el evaluador con comprobaciones baratas, basadas en reglas, antes de confiar en un solo número. Luego tus pronósticos se parten limpiamente en dos: los que tratan de cosas predecibles son nítidos, y los que tratan de cosas genuinamente inciertas son mediocres — y la verdadera victoria es un sistema lo bastante honesto para decirte cuál es cuál. Y aprendes no reentrenando una caja negra sino llevando un cuaderno legible de lecciones que un humano puede auditar.
Hagámoslo concreto. Si alguien se ofreciera a predecir tu facturación exacta del próximo trimestre al euro, harías bien en ser escéptico — eso es un problema tipo España-contra-Cabo-Verde, en su mayoría ruido. Pero “qué clientes están derivando en silencio hacia marcharse”, “qué proveedor ha subido los precios más rápido que el mercado”, “qué factura de esta semana no se parece a las demás” — esos son problemas tipo quién-será-titular: la respuesta ya está en tus propios datos, solo hace falta algo que los lea cada mañana, se puntúe a sí mismo con honestidad, y te diga cuán seguro está. Y — la lección de Valery — no te quedes en “quién estará de turno”; pregunta “y cómo es probable que vaya ese turno”, porque las dos son preguntas distintas. Eso es previsión de demanda, detección de abandono, monitorización de riesgo de proveedores, detección de anomalías — y la misma forma de sistema funciona igual de bien apuntada a tus propios datos detrás de tu propio cortafuegos, no a la web abierta. Los futbolistas solo hacen que el marcador sea público y las apuestas lo bastante bajas como para mostrarlo entero, fallos incluidos.
Vale. Volvamos al juego.
Qué cambié para la segunda jornada — y qué espero
Casi todo lo útil de esta semana vino de los fallos, no de los aciertos. Las lecciones no solo quedaron por escrito; se realimentaron en dos conjuntos concretos de cambios antes de que arrancara la siguiente ronda — uno para las predicciones de alineación, otro para las de marcadores. Para que conste, esto es lo que de verdad es distinto, y qué espero de cada cosa.
Las predicciones de alineación (quién jugará) — sobre todo arreglando calibración y puntos ciegos:
- Bajar el medio demasiado confiado. La banda del 20–40% iba unos 18 puntos caliente, así que se recorta; las bandas del 40–60% y del 60–80% iban unos 8 puntos altas, así que se ajustan. La banda del 80–100% se deja en paz — ya era honesta.
- Dejar de tratar como fijos solo los nombres famosos. La jornada inaugural estuvo llena de habituales poco vistosos de naciones pequeñas que teníamos aparcados al 2–15% y que fueron titulares igualmente — así que el investigador ahora le da crédito a un titular establecido sin importar su perfil, y trata con más recelo a un nombre grande que ha perdido su sitio (la fama no es el escalafón actual).
- Marcar la bola con efecto de la jornada inaugural. Un entrenador descansando a un titular en forma — la predicción que me costó con aquel portero suplente — es ahora un riesgo conocido, no una sorpresa.
- Mantener frescos los datos. La guarda contra caducidad más un refresco completo la mañana de cada partido significan que no habrá más fantasmas de tres semanas en la nota.
Lo que espero: la calibración se aprieta, sobre todo esa banda media. El titular del 84% quizá no salte — pero se vuelve más honesto, que es el punto.
Las predicciones de marcador — aquí las lecciones tratan de cómo se comportan realmente los goles:
- Desacoplar confianza de marcador. La baja confianza dejó de significar “pocos goles”, así que un desajuste genuino puede pronosticarse como la goleada que es, no como un educado 3–0 (Alemania 7–1, Suecia 5–1 son lo que pareció ese fallo).
- Cubrirse ante el favorito claro. Contra un rival que defiende replegado con un buen portero, esperar el empate mucho más a menudo — y dejar de estar 85% seguro de un 3–0 (España 0–0; el grupo de 1–1).
- Romper el 1–1 reflejo. En un cara o cruz donde un lado domina el balón, inclinarse por una victoria ajustada de ese lado en vez de partir la diferencia.
- Sin ventaja de local en un torneo neutral (salvo los anfitriones).
- Ensanchar la confianza donde es un sorteo. Decir “este es un cara o cruz” en voz alta en vez de fingir precisión — esa brecha de 65-frente-a-57 es la que hay que cerrar.
Lo que espero: la precisión sobre el ganador debería despegar del 46%. Sigo sin prometer buenos marcadores — la aleatoriedad es real — pero la confianza debería al menos empezar a decir la verdad sobre sí misma.
El tercer cambio es el silencioso: la evaluación en sí está ahora fechada, codificada por color, autocorrectiva y pública, así que nada de lo anterior puede halagarme en la oscuridad.
Lo cual prepara la prueba honesta. Tras la segunda jornada publicaré este mismo boletín de nuevo — y verás, en público, si estos cambios movieron de verdad los números o solo sonaban bien sobre el papel. Esa, al final, es la única forma de distinguir un sistema que aprende de uno que meramente informa. Todo el asunto se mantiene a la vista, puntuado contra la realidad, actualizado tras cada ronda — puedes verlo mejorar, o fallar al hacerlo, sin tener que creerme en nada.
Una última reflexión, y te dejo ir. Lo más útil de esta semana no vino de que la IA fuera lista. Vino de verme obligado a responder con honestidad a dos preguntas aburridas: ¿puedo confiar en mi propio marcador?, y ¿cuáles de mis predicciones merecen de verdad confianza? A esas preguntas les da igual si el tema es fútbol, fletes o facturas — y, según mi experiencia, la mejora a un modelo más sofisticado se persigue mucho antes de responder a cualquiera de las dos. Si tu trabajo funciona a base de pronósticos y nunca has acabado de fiarte del panel que los evalúa, ya sabes cuál es el problema más interesante que masticar — y la primera jugada honesta es simplemente ver caer la próxima jornada en la página pública antes de dar por bueno nada de lo que he dicho. Si en algún punto de aquí viste tu propio mundo en vez de un campo de fútbol, pues — ya sabes dónde encontrarme.