cat artikel/ai-predictions-graded-matchday-1.mdx
Comunio World Cup 2026 · Teil 2Prognosen, ehrlich benotet: stark darin, wer spielt – schwach beim Ergebnis
Nach einer Spielrunde meiner WM-Fantasy-KI benote ich ihre Prognosen öffentlich: zuverlässig bei der Startelf, schwach beim Ergebnis – und warum genau diese Trennung der eigentliche Lerneffekt für jedes Unternehmen ist.
22. Juni 2026 · von Daniel Deusing · ~23 Min. Lesezeit #ai #agents #football
Im ersten Artikel habe ich über ein Team aus KI-Agenten geschrieben, das ich für eine Fantasy-Liga zur WM 2026 gebaut habe – und ich habe ein Versprechen gegeben: Sobald die Spiele gelaufen sind, komme ich zurück und benote die Prognosen öffentlich. Richtig, mit allen Fehlern offen auf dem Tisch, nicht nur mit den Treffern. Die erste Runde der Gruppenspiele ist durch. Hier ist das Zeugnis.
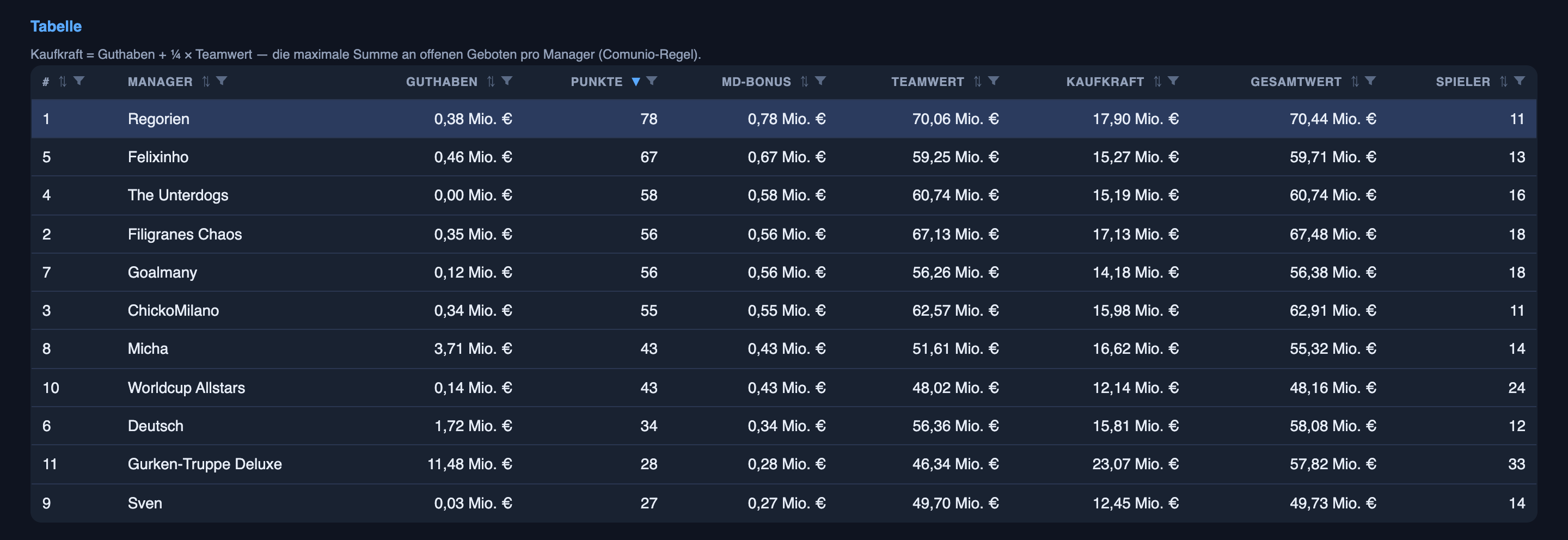
Dem Kader selbst geht es gut – nach einer Runde steht er ganz oben in unserer kleinen Freundesliga. Aber ich will ehrlich sein, warum: Das liegt vor allem am Kaufen und Verkaufen aus Teil eins, nicht an den Spielprognosen. Die Prognosen sind eine andere, interessantere Geschichte – und die Schlagzeile ist eine Spaltung, mit der ich nicht gerechnet hatte:
Der spektakuläre Teil – Ergebnisse tippen – ist im Moment der Teil, in dem das System am schwächsten ist. Der unscheinbare Teil – vorherzusagen, wer tatsächlich in der Startelf steht – ist der, in dem es schon zuverlässig ist. Der ehrliche Grund für die Lücke ist nicht, dass das eine Daten liest und das andere rät – beides stützt sich auf Daten (Teamnews und Aufstellungs-Leaks für die Startelf; Wettmärkte und Form für die Ergebnisse), und beides enthält echtes Raten. Der Unterschied ist, wie viel von der Antwort vor dem Anpfiff schon feststeht. Wer beginnt, ist größtenteils im Voraus entschieden, also bringen gute Informationen einen weit – abgesehen von der gelegentlichen Trainerüberraschung, die sich von außen nicht ablesen lässt. Ein Spielergebnis wird größtenteils über neunzig Minuten Chaos entschieden, also engen selbst die besten Informationen es nur ein; festnageln können sie es nicht. Dasselbe System, zwei Probleme mit sehr unterschiedlich viel eingebautem Zufall – und genau diese Unterscheidung, nicht der Fußball, ist der nützliche Teil.
Aber vor allen Benotungen noch ein Geständnis über das Benoten selbst – denn genau da steckt die erste echte Lektion.
Kurze Zusammenfassung, falls du Teil eins verpasst hast: Ich bin in einem Fantasy-Spiel, in dem man echte Fußballer in einer Blindauktion kauft und verkauft – verdeckte Gebote, niemand sieht die der anderen, das höchste gewinnt – und ein Team aus KI-Agenten erledigt die tägliche Hausaufgabe. In diesem Artikel geht es um das andere Versprechen, das ich dort gegeben habe: dass das System seine eigenen Prognosen an der Realität misst, öffentlich, ab der Nacht des ersten Anpfiffs.
Ich musste erst den Bewerter reparieren, bevor ich ihm trauen konnte
Das ist der Teil, den man leicht überspringt. Als die ersten Ergebnisse hereinkamen, spuckte meine schicke neue Genauigkeitsseite Zahlen aus, denen ich nicht trauen konnte – nicht weil die Prognosen gut oder schlecht waren, sondern weil das Benoten Bugs hatte. Drei davon lohnt es sich zu nennen, denn jeder ist ein Fehler, den jedes Unternehmen beim ersten Versuch macht, ein KI-System ehrlich zu messen.
Es benotete veraltete Prognosen. Einer meiner Spieler, der österreichische Mittelfeldspieler Laimer, stand in der Auswertung mit 95 % als „spielt nicht“ – und dann spielte er die vollen neunzig Minuten. Das System sah furchtbar falsch aus. Aber es lag diese Woche nicht falsch: Diese 95 % waren eine drei Wochen alte Einschätzung, die vor dem Spiel nie aktualisiert wurde. Ich benotete eine Prognose, die das System praktisch vergessen hatte, je gemacht zu haben. Müll rein, Müllnote raus.
Es konnte zwei Personen nicht auseinanderhalten. Drei Spieler – darunter ein englischer Verteidiger namens O’Reilly – wurden als „hat nicht gespielt“ markiert, obwohl sie das ganze Spiel über in der Startelf standen. Der Grund ist langweilig und wichtig: Der Spieler in den Live-Aufstellungsdaten und der Spieler in meiner Prognose waren derselbe Mensch, erfasst unter zwei leicht unterschiedlichen Namen, und das System behandelte sie als Fremde. Das ist ein Lehrbuchfall von Entity Resolution.
Es vergab einen Heimvorteil bei einem Turnier ohne Heimspiele. Das Modell gab dem zuerst gelisteten Team klammheimlich einen Heimplatz-Vorteil – aber WM-Gruppenspiele werden auf neutralem Boden gespielt (außer beim Gastgeber). Eine kleine Annahme, übernommen aus dem normalen Ligafußball, die leise alles verzerrte.
Beachte, was diese drei gemeinsam haben: Keiner war die KI, die „dumm“ war. Die Agenten taten ungefähr, was man ihnen gesagt hatte. Die Fehler steckten in der Messung – in der Verrohrung, die entscheidet, was als richtig zählt. Und das ist die Lektion, die ich für jeden unterstreichen würde, der echtes Budget in ein KI-Projekt steckt: Das Ding zu bauen ist die einfache Hälfte. Einen Maßstab zu bauen, dem man wirklich trauen kann, ist die schwere Hälfte – und es ist die Hälfte, die übersprungen wird. Eine Zahl, die man nicht verteidigen kann, ist schlimmer als gar keine Zahl, denn sie macht einen selbstsicher und falsch zugleich.
Die Korrekturen waren größtenteils langweilig, und genau das ist der Punkt. Ein Staleness Guard – ein simples Stück Code, keine KI, das jede Prognose verwirft, die für den zu benotenden Spieltag nicht aufgefrischt wurde – läuft jetzt in jedem Zyklus, und am Morgen jedes Spiels wird ein frischer Satz Prognosen festgezurrt (keine 21 Tage alten Geister mehr). Eine wachsende Alias-Map – eine Nachschlagetabelle mit Namensentsprechungen – bringt dem System bei, dass „Nico O’Reilly“ und „O’Reilly“ ein und derselbe Mann sind. Die Neutralplatz-Regel ist jetzt festgeschrieben. Aufstellungen werden gegen den passenden Wikipedia-Spielartikel geprüft – serverseitig gerendert, schnell, mit der bestätigten Startelf und den Auswechselspielern ein paar Stunden nach dem Schlusspfiff, jeder Ausreißer mit Quellenangabe. Und Ergebnisse bekommen jetzt einen ehrlichen Vier-Farben-Code, den du weiter unten siehst. Das Prinzip darunter: Setze das teure, clevere Werkzeug (die KI) nur dort ein, wo wirklich Urteilsvermögen gebraucht wird, und umgib es überall dort, wo eine Garantie zählt, mit billigem, langweiligem, unzerstörbarem Code.
Die gute Nachricht: Wer spielt, ist größtenteils wissbar – und das lesen wir gut
Jetzt die Noten. Beginnen wir mit dem, was funktioniert hat, denn es hat mich überrascht, wie gut es funktioniert hat.
Jeden Tag erzeugt das System für jeden Spieler eine Zahl, die es p_start nennt. Dann findet das Spiel statt, und wir prüfen nach.
Der richtige Weg, einen Konfidenzwert zu beurteilen, ist nicht „war er richtig“. Es ist Kalibrierung.
An diesem Maßstab gemessen hat das System gut abgeschnitten. Über 172 Startelf-Einschätzungen in der ersten Runde (die veralteten herausgeworfen) lag es in 84 % der Fälle richtig – aber die Form zählt mehr als die Schlagzeile:
- Wenn es einem Spieler eine 0–20 %-Chance auf einen Startplatz gab (71 Einschätzungen), begann er in etwa 13 % der Fälle. Bei den Außenseitern fast genau richtig.
- Wenn es 80–100 % sagte (44 Einschätzungen), begann der Spieler in 91 % der Fälle. Wenn dieses System sich sicher ist, kann man ihm glauben.
- Die Schwachstelle war der matschige Mittelbereich. Im 20–40 %-Band (nur 24 Einschätzungen) implizierte es grob eine Eins-zu-drei-Chance, aber diese Spieler begannen nur etwa eines von acht Malen – klar überheblich.

Eine faire Einschränkung: Das ist eine Runde, und manche Bänder enthalten nur ein paar Dutzend Einschätzungen, also lies es als Signal, das man im Auge behält, nicht als in Stein gemeißeltes Urteil. Aber warum ist das die stabilere Hälfte? Weil wer beginnt, im Voraus weitgehend wissbar ist: Teamnews, eine Pressekonferenz, die Gewohnheiten eines Trainers, ein Verletzungsbericht. Der Großteil der Arbeit ist diszipliniertes Lesen – das Zusammentragen dessen, was ohnehin schon öffentlich ist, schneller und konsistenter, als ich es von Hand täte – und nur ein Bruchteil ist echtes Raten: die Rotationsentscheidungen, der Trainer, der eine Überraschung aus dem Hut zaubert, die kein Aufstellungs-Lesen einfangen kann. Genau diese Mischung zeigt die Kalibrierung: das Lesen ist, warum die sicheren Bänder treffen, das Raten ist, warum das Mittelband wackelt.
Was es bei meinen eigenen Spielern richtig und falsch lag
Abstrakte Kalibrierung ist eine Sache. Hier ist, was sie konkret für Spieler bedeutete, die ich besaß, mit denen ich gewann und an denen ich verlor – das ehrliche Hauptbuch. Jede Einschätzung lebt auf demselben täglichen Bildschirm: jeder Spieler mit Startwahrscheinlichkeit, Einsatzwahrscheinlichkeit, einem Halten-oder-Verkaufen-Urteil und einer Notiz, die ihre Quellen verlinkt.
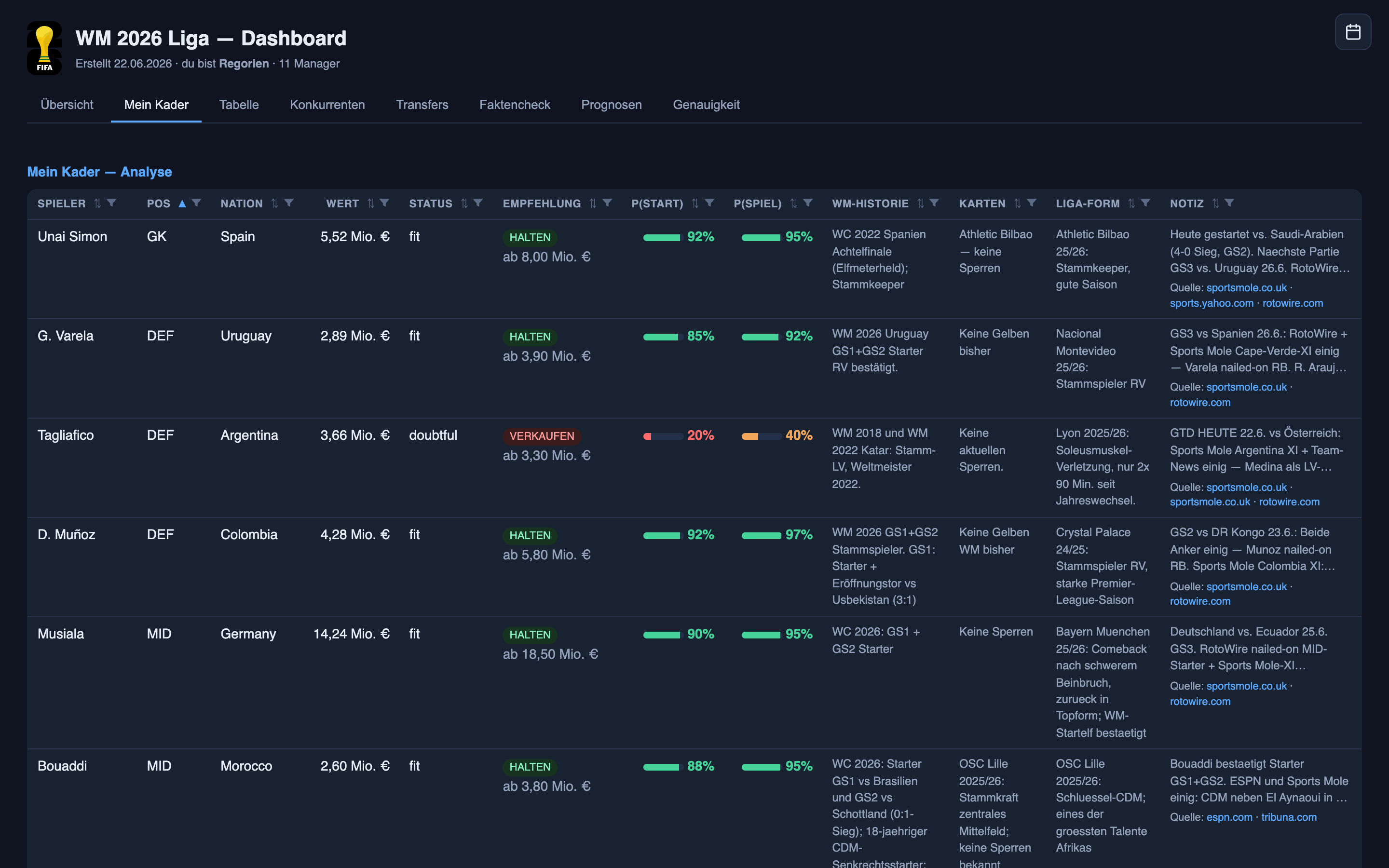
Die schwierige, die es richtig lag: Unai Simón. Spaniens Torhüter hatte eine holprige Vorbereitung, die Presse war voller Rotationsgerede, und der Trainer gab in beide Richtungen kein klares Wort – eine wirklich undurchsichtige Entscheidung, kein Selbstläufer. Das System blieb auf der Seite, dass er beginnt, und hielt diese Linie durch den ganzen Lärm. Er begann und spielte alle neunzig Minuten. Das ist das System, das genau das tut, was ich am meisten von ihm will: Das Bild von außen sagte „vielleicht“, das System sagte „er beginnt“, und es lag richtig. Das Lesen einer undurchsichtigen Lage, keine Tatsache, die von einem Aufstellungszettel abgeschrieben wurde – und genau diese Art trifft die Wer-spielt-Seite öfter als nicht.
Der Fehlschuss, der mich was gekostet hat: Crepeau. Ich verkaufte Kanadas Keeper, weil das System ihn nur mit 40 % für einen Startplatz sah – eine Tendenz Richtung Bank. Er begann alle neunzig Minuten und holte vier Punkte, die ich nicht mehr hatte. Ein echter Verlust, und einen, den ich dem Modell anlasten kann: 40 % war kein „nein“, es war ein Münzwurf, als Tendenz verkleidet, und ich behandelte ihn als Entscheidung.
Die andere Seite derselben Medaille: Asare. Ich kaufte Ghanas Keeper, weil das System ihn auf 55 % setzte – eine Tendenz Richtung Startelf. Er begann nicht; er kam nur herein, als Ghanas Stammkeeper Ati Zigi verletzt raus musste. Zwei Transfers, entgegengesetzte Richtungen, dieselbe Ursache: Im 40–60 %-Band ist die Konfidenz des Systems kaum besser als ein Münzwurf, und ich verwechsle „kaum“ immer wieder mit „wahrscheinlich“.
Die selbstsichere, die trotzdem danebenlag: Angulo. Der ecuadorianische Stürmer – ein Held aus Teil eins – stand bei 78 % für einen Startplatz. Er begann nicht; er kam in der 56. Minute von der Bank. Das ist eine Einschätzung im 60–80 %-Band, genau dem, das die Kalibrierungskurve etwa acht Punkte zu heiß zeigt. Anekdote und Daten sind sich also einig: Wenn dieses System „ziemlich wahrscheinlich“ sagt, zieh ein bisschen ab.
Und dann die Überraschungen, die kein Modell hätte lesen können: ein australischer Ersatztorhüter, den wir bei 2 % hatten, begann die vollen neunzig Minuten, weil der Trainer seine Nummer eins am Morgen des Spiels auf die Bank setzte; ein kolumbianischer Mittelfeldspieler bei 3 % spielte achtzig Minuten. Reine Trainerlaune, in einer Kabine entschieden, von außen unwissbar. Das sind die unvermeidbaren Fehlschüsse – und das Ehrliche ist, sie zu zählen, nicht wegzuerklären.
Die tiefere Falle: vorherzusagen, wer spielt, ist nicht vorherzusagen, wie er spielt
Hier ist die, die mich am meisten gelehrt hat. Valery, ein tunesischer Verteidiger, begann und spielte 72 Minuten – das System hielt seinen Einsatz für wahrscheinlich, und das Aufstellungs-Lesen war richtig. Das Problem ist, dass Tunesien 5:1 auseinandergenommen wurde, und ein Verteidiger auf der falschen Seite davon ging mit −2 Punkten vom Platz. Ich wählte einen Spieler, von dem das System korrekt sagte, er würde spielen, und verlor trotzdem Punkte.
Diese Lücke zählt überall. „Wird diese Person Schicht haben“ und „wird diese Schicht gut laufen“ sind verschiedene Fragen, und ein System, das in der ersten gut ist, kann in der zweiten nutzlos sein, wenn man sie verwechselt. Die Lösung ist kein besseres Aufstellungsmodell – sie besteht darin, die zweite Frage explizit hinzuzufügen: Wer spielt gegen wen, und was ist das erwartete Ergebnis, und wie schlimm kann es ausgehen? Ein Starter in einem Team, das gleich überrannt wird, ist eine Falle, die die Aufstellungsprognose allein nicht sehen kann.
Die schlechte Nachricht: das Ergebnis zu tippen ist die schwache Hälfte – und wird es teils immer sein
Womit wir bei den Ergebnissen wären, wo das System schlicht nicht gut war.
Über alle 24 Auftaktspiele tippte es den Sieger in 46 % der Fälle richtig – in mehr als der Hälfte falsch – und das genaue Ergebnis in nur 8 % (zwei von 24 Spielen). Ein Blindtipp über Sieg, Unentschieden und Niederlage landet bei rund einem Drittel, das Modell tippt also nicht zufällig; es trifft sie nur nicht gut.
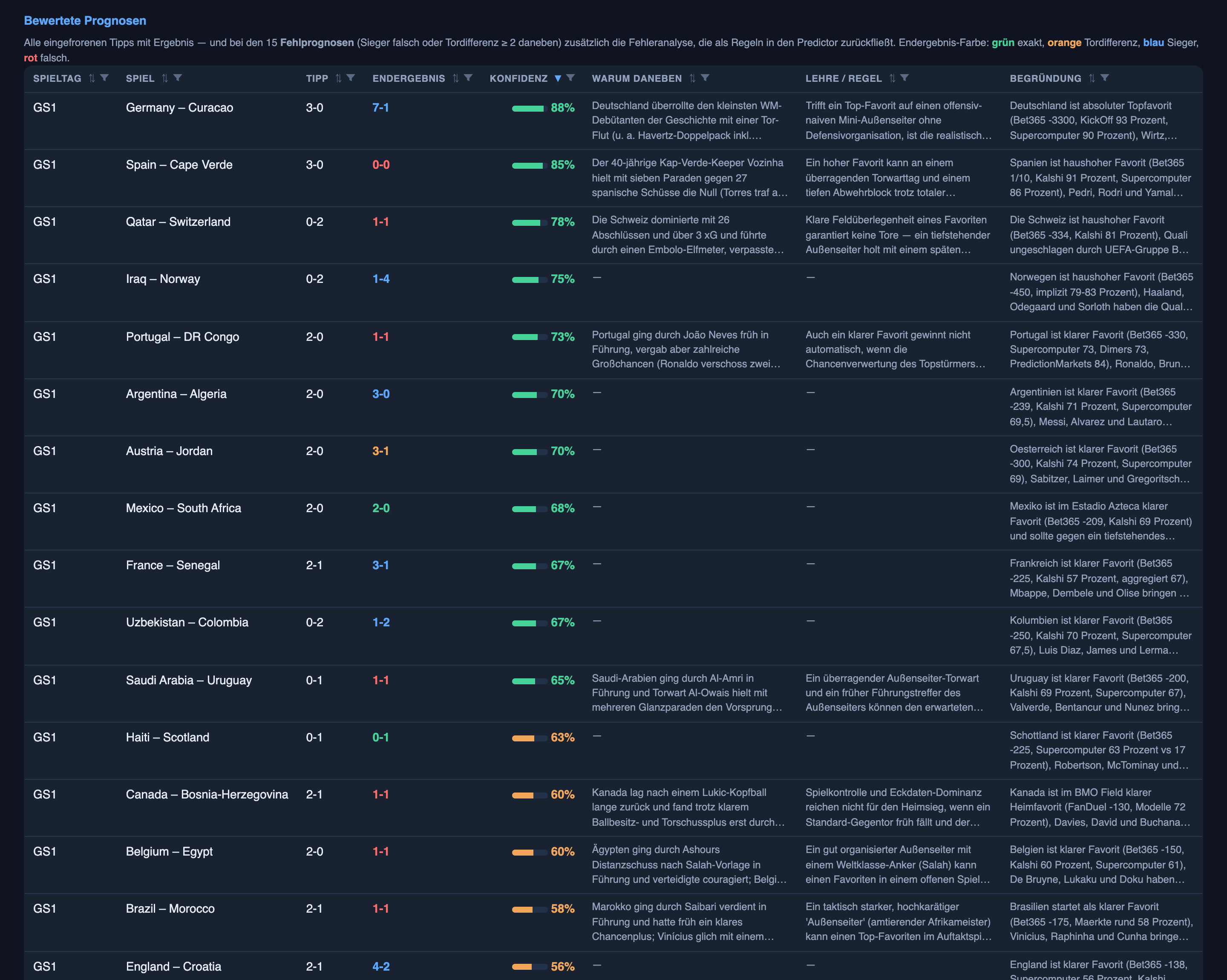
Drei Spiele erzählen die ganze Geschichte.
Spanien 0:0 Kap Verde – das wirklich nicht Vorhersehbare. Das System tippte Spanien auf einen 3:0-Sieg mit 85 % Konfidenz. Spanien ist ein Riese; Kap Verde war WM-Debütant; die Wettmärkte waren einer Meinung; alles deutete in eine Richtung. Es endete 0:0. Hier gibt es keine Lektion außer Demut: Manchmal läuft ein klarer Favorit in eine massierte Abwehr und einen Torhüter, der den Nachmittag seines Lebens hat, und keine noch so große Intelligenz sieht ein konkretes 0:0 voraus. Die ehrliche Korrektur lautet nicht „sag es besser voraus“ – sie lautet „sei in einem einzelnen torarmen Spiel nicht zu 85 % von irgendwas überzeugt“.
Türkei 0:2 gegen Australien – das, auf das wir wohl anders hätten tippen sollen. Hier favorisierte das System tatsächlich die Türkei und tippte sie auf einen 2:1-Sieg mit 55 %. Sie verloren 0:2 und sahen schlecht aus. Hätten wir es wissen können? Teilweise – die jüngste Form und die Kaderbreite eines Teams sind lesbar, und 55 % war ohnehin schon fast ein Münzwurf, das Modell war also nicht sicher, sondern eher leicht daneben. Das ist der Mittelweg: nicht unvorhersehbar wie Spanien, kein systematischer Bug – nur eine Tendenz, die wohl in die andere Richtung hätte gehen sollen.
Tunesien 1:5 gegen Schweden – das Debakel, das wir unterschätzt haben. Das System tippte einen knappen schwedischen Sieg, 1:0. Schweden gewann 5:1. Es traf den Sieger richtig und die Größenordnung völlig daneben – und genau dieser blinde Fleck ist, warum Valerys Minuspunkte mich überrascht haben. Das ist der entgegengesetzte Fehler zu Spanien: dort waren wir zu mutig bei einem Favoriten, der unentschieden spielte; hier zu zaghaft bei einem Ungleichgewicht, das zum Massaker wurde.
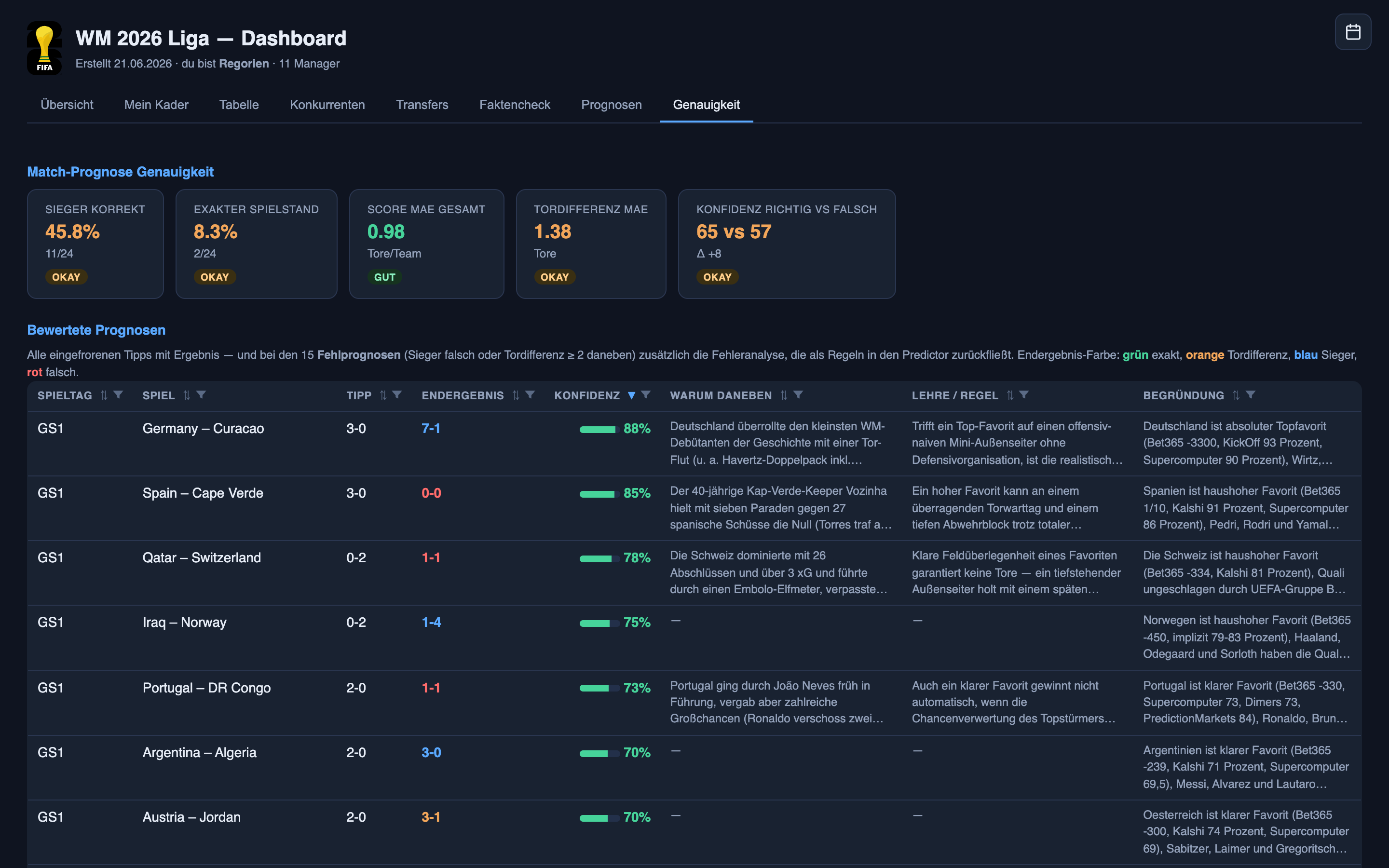
Zusammengenommen sind diese drei die eigentliche Diagnose. Das System ist nicht einfach „zu selbstsicher“ oder „zu vorsichtig“ – es liegt falsch darüber, wie Fußballergebnisse sich verhalten. Tore sind selten, ein ganzes Spiel kann an einem hängen, und seltene Ereignisse werden von Zufall dominiert, den kein Modell entfernen kann, weil er noch nicht passiert ist. Es gibt echtes Signal, auf das man sich stützen kann – die Wettmärkte, die Formkurve, das bessere Team, das öfter gewinnt als nicht, und das System nutzt alles davon –, aber es bleibt unter diesem Zufall begraben. Das mit Abstand Wichtigste, das man über Vorhersage verstehen muss, im Fußball wie im Geschäft: Manche Fragen haben Antworten, die nur darauf warten, gefunden zu werden, und manche sind echt dem Zufall überlassen. Ein gutes System muss wissen, was was ist – laut, wo es Signal gibt, demütig, wo es nur Rauschen gibt. Diese Woche war meines nicht demütig genug: Seine Konfidenz trennte seine Treffer kaum von seinen Fehlschüssen (etwa 65 % sicher, wenn es richtig lag, 57 %, wenn es falsch lag). Diese Lücke zu schließen zählt mehr, als ein paar korrekten Ergebnissen hinterherzujagen – und es ist eines der ersten Dinge, die ich für den zweiten Spieltag geändert habe.
Wie die Prognosen entstehen – und wie das System tatsächlich lernt
Es lohnt sich, den Vorhang aufzuziehen, denn der „Wie es lernt“-Teil ist der Punkt, an dem es aufhört, um Fußball zu gehen.
Vor jedem Spieltag geht ein Researcher-Agent Nation für Nation durch und setzt das Bild zusammen – wahrscheinliche Aufstellungen, Verletzungen, Form, wer rotiert. Ein Predictor-Agent macht daraus ein Ergebnis und eine Konfidenz. Nichts davon sind fest verdrahtete Regeln, die ich vor Monaten geschrieben habe; die Agenten lesen jedes Mal die aktuelle Welt und denken neu. Das ist der Unterschied zwischen einen Report zu automatisieren und einen Analysten einzustellen, der zufällig aus Software besteht.
Aber neu zu denken ist nicht dasselbe wie zu lernen. Diese Woche habe ich deshalb ein neues Teil hinzugefügt: einen Evaluator-Agenten – stell dir einen Qualitätsprüfer vor, der nach der Schicht hereinkommt, sieht, was die Linie falsch gemacht hat, und die Muster aufschreibt. Nach den Spielen holt er die echten Ergebnisse und Aufstellungen, bewertet beide und – der entscheidende Schritt – destilliert die Fehlschüsse zu einer kurzen Liste klar formulierter Lektionen. Kein Datenberg; eine Handvoll Muster, entdoppelt, jedes mit Belegen und einer konkreten Regeländerung. Einige der Lektionen, die er sich diese Woche selbst geschrieben hat:
„Favoriten gegen tief stehende Außenseiter mit starkem Torhüter wurden systematisch überbewertet – Spielfeldüberlegenheit wurde nicht zu Toren; der Außenseiter holte sich ein Unentschieden durch einen späten Standard.” Belege: Spanien–Kap Verde, Katar–Schweiz, Belgien–Ägypten.
„Kantersiege gegen offensiv naive Underdogs wurden unterschätzt, weil niedrige Konfidenz fälschlich mit wenigen Toren gleichgesetzt wurde. Entkopple Konfidenz vom Ergebnis.” Belege: Deutschland, getippt 3:0, gewann 7:1; Schweden 1:0 → 5:1.
„WM-Gruppenspiele sind auf NEUTRALEM Boden – es gibt keinen Heimvorteil außer für den Gastgeber. Dem zuerst gelisteten Team wurde fälschlich ein Heimvorteil zugesprochen.”
Das ist die Schleife, die sich schließt. Vor dem nächsten Spieltag liest der Predictor seine Lektionen-Datei und der Researcher seine eigene, und beide passen sich an. Die Aufstellungs-Seite hat sich sogar selbst diese Notiz geschrieben – „das 20–40 %-Band läuft heiß; das 80–100 %-Band ist gut kalibriert, vertrau ihm” – das System, das seine eigene Schwachstelle diagnostiziert, schriftlich, für das nächste Mal.
Jetzt die ehrliche Grenze, denn hier übernimmt sonst der Hype. Wenn ich sage, das System „lernt“, meine ich nicht, dass es über Nacht irgendein riesiges Gehirn umverdrahtet. Es gibt zwei Wege, wie eine KI sich verändern kann. Der eine ist teuer und langsam – das Modell selbst neu zu trainieren, am Ende eine Blackbox. Der andere ist das, was ich tue: Die Lektionen liegen in einer einfachen Textdatei, die das Modell zu Beginn jedes Laufs liest, wie ein scharfsinniger neuer Mitarbeiter, der ein Notizbuch mit „Dinge, die ich falsch gemacht habe und was ich anders machen werde“ führt und es vor jeder Aufgabe durchgeht. Es ist billig, es ist sofort wirksam, und – der Teil, der fürs Geschäft zählt – es ist inspizierbar: Ich kann jede Lektion lesen, mit ihr streiten, eine schlechte löschen. Und schlechte gibt es – ein Evaluator kann eine plausibel klingende Lektion schreiben, die in Wahrheit falsch ist, und genau deshalb liest ein Mensch sie, bevor sie die nächste Runde füttern. Ein System, dessen Lernen man lesen und überstimmen kann, ist eines, das man in einem Unternehmen laufen lassen kann. Eine Blackbox, die „einfach besser wird“, ist eine, an der man nie am Wirtschaftsprüfer vorbeikommt.
Und es gibt eine Decke. Die Schleife kann Verzerrungen beheben – den Phantom-Heimvorteil, das reflexhafte 1:1, das überhebliche Mittelband. Die sind real, systematisch, korrigierbar, und ich erwarte, dass sie nächste Runde schrumpfen. Was sie nicht beheben kann, ist der Zufall – das unvermeidbare Glück in einem torarmen Spiel. Kein Notizbuch macht eine 0:0-Überraschung vorhersehbar. Das kluge Ziel ist also nicht „Ergebnisse besser vorhersagen“. Es ist „wissen, welche Einschätzungen Konfidenz verdienen und welche ehrlich gesagt Münzwürfe sind“ – und da hilft die Schleife wirklich.
Lass den Fußball weg
Lies die letzten paar Abschnitte noch einmal, aber streiche das Wort „Fußball“.
Ein System macht Prognosen. Du bewertest sie ehrlich – und das Erste, was du findest, ist, dass deine Bewertung selbst unzuverlässig war: veraltete Eingaben benoten, zwei Datensätze derselben Entität verwechseln, eine versteckte Annahme aus dem falschen Kontext mitschleppen. Also reparierst du den Bewerter mit billigen, regelbasierten Prüfungen, bevor du einer einzigen Zahl traust. Dann teilen sich deine Prognosen sauber in zwei Hälften: die über wissbare Dinge sind scharf, und die über echt unsichere Dinge sind mittelmäßig – und der eigentliche Gewinn ist ein System, das ehrlich genug ist, dir zu sagen, was was ist. Und du lernst nicht, indem du eine Blackbox neu trainierst, sondern indem du ein lesbares Notizbuch mit Lektionen führst, das ein Mensch prüfen kann.
Mach es konkret. Wenn dir jemand anböte, deinen exakten Umsatz im nächsten Quartal auf den Euro genau vorherzusagen, hättest du recht, skeptisch zu sein – das ist ein Spanien-gegen-Kap-Verde-Problem, größtenteils Rauschen. Aber „welche unserer Kunden driften leise Richtung Absprung“, „welcher Lieferant hat seine Preise schneller als der Markt angezogen“, „welche Rechnung diese Woche sieht anders aus als die übrigen“ – das sind Wer-spielt-Probleme: Die Antwort liegt schon in deinen eigenen Daten, irgendwas muss sie nur jeden Morgen lesen, sich ehrlich selbst bewerten und dir sagen, wie sicher es ist. Und – die Valery-Lektion – hör nicht bei „wer Schicht hat“ auf; frag „und wie läuft diese Schicht wahrscheinlich“, denn das sind zwei verschiedene Fragen. Das ist Bedarfsprognose, Churn-Erkennung, Lieferanten-Risiko-Monitoring, Anomalie-Erkennung – und dieselbe Art System läuft genauso gut auf deine eigenen Daten hinter deiner eigenen Firewall gerichtet, nicht auf das offene Netz. Die Fußballer machen die Anzeigetafel nur öffentlich und den Einsatz niedrig genug, um das Ganze zu zeigen, Fehlschüsse inklusive.
Okay. Zurück zum Spiel.
Was ich für den zweiten Spieltag geändert habe – und was ich erwarte
Fast alles Nützliche diese Woche kam aus den Fehlschüssen, nicht aus den Treffern. Die Lektionen wurden nicht nur aufgeschrieben; sie flossen vor dem Anpfiff der nächsten Runde in zwei konkrete Änderungspakete zurück – eines für die Aufstellungs-Einschätzungen, eines für die Ergebnisse. Aktenkundig, hier ist, was tatsächlich anders ist und was ich von jedem erwarte.
Die Aufstellungs-Einschätzungen (wer spielt) – vor allem Kalibrierung und blinde Flecken beheben:
- Die überhebliche Mitte herunterziehen. Das 20–40 %-Band lief etwa 18 Punkte zu heiß, also wird es gekürzt; die 40–60 %- und 60–80 %-Bänder waren rund 8 Punkte zu hoch, also werden sie getrimmt. Das 80–100 %-Band bleibt in Ruhe – es war schon ehrlich.
- Nicht nur die berühmten Namen als gesetzt behandeln. Die erste Runde war voll von unscheinbaren Stammspielern kleinerer Nationen, die wir bei 2–15 % geparkt hatten und die trotzdem begannen – also rechnet der Researcher einem etablierten Starter jetzt unabhängig vom Profil Anerkennung an und behandelt einen großen Namen, der seinen Platz verloren hat, mit mehr Misstrauen (Ruhm ist nicht die aktuelle Hackordnung).
- Die Auftakt-Überraschung markieren. Ein Trainer, der einen fitten Stammspieler schont – die Einschätzung, die mich bei diesem Ersatztorhüter etwas gekostet hat – ist jetzt ein bekanntes Risiko, keine Überraschung.
- Die Eingaben frisch halten. Der Staleness Guard plus ein vollständiger Refresh am Morgen jedes Spiels bedeutet keine drei Wochen alten Geister mehr in der Note.
Was ich erwarte: Die Kalibrierung zieht sich enger zusammen, besonders dieses Mittelband. Die Schlagzeile von 84 % springt vielleicht nicht – aber sie wird ehrlicher, und darum geht es.
Die Ergebnis-Einschätzungen – hier drehen sich die Lektionen darum, wie Tore sich tatsächlich verhalten:
- Konfidenz vom Ergebnis entkoppeln. Niedrige Konfidenz bedeutet nicht mehr „wenige Tore“, sodass ein echtes Ungleichgewicht als das Debakel getippt werden kann, das es ist, nicht als höfliches 3:0 (Deutschland 7:1, Schweden 5:1 sind, wie dieser Fehlschuss aussah).
- Den klaren Favoriten absichern. Gegen einen tief verteidigenden Außenseiter mit gutem Keeper das Unentschieden viel häufiger erwarten – und aufhören, zu 85 % von einem 3:0 überzeugt zu sein (Spanien 0:0; die Häufung von 1:1).
- Das reflexhafte 1:1 durchbrechen. In einem Münzwurf, in dem eine Seite den Ball dominiert, zu einem knappen Sieg für diese Seite tendieren, statt die Differenz zu teilen.
- Kein Heimvorteil bei einem neutralen Turnier (außer für den Gastgeber).
- Die Konfidenz weiten, wo es eine offene Sache ist. „Das ist ein Münzwurf“ laut aussprechen, statt Präzision vorzutäuschen – diese 65-gegen-57-Lücke ist die, die zu schließen ist.
Was ich erwarte: Die Sieger-Genauigkeit sollte über die 46 % klettern. Ich verspreche immer noch keine guten Ergebnisse – der Zufall ist real –, aber die Konfidenz sollte zumindest anfangen, die Wahrheit über sich selbst zu sagen.
Die dritte Änderung ist die stille: Das Benoten selbst ist jetzt datiert, farbcodiert, selbstkorrigierend und öffentlich, sodass nichts davon mich im Dunkeln schmeicheln kann.
Was den ehrlichen Test aufstellt. Nach dem zweiten Spieltag veröffentliche ich dasselbe Zeugnis wieder – und du wirst öffentlich sehen, ob diese Änderungen die Zahlen tatsächlich bewegt haben oder nur auf dem Papier gut klangen. Das ist am Ende die einzige Art, ein System, das lernt, von einem zu unterscheiden, das bloß berichtet. Das Ganze bleibt offen, an der Realität gemessen, nach jeder Runde aktualisiert – du kannst zusehen, wie es besser wird, oder scheitert, ohne mir irgendetwas auf mein Wort glauben zu müssen.
Ein letzter Gedanke, dann lasse ich dich gehen. Das Nützlichste diese Woche kam nicht daher, dass die KI clever war. Es kam daher, dass ich gezwungen war, zwei langweilige Fragen ehrlich zu beantworten: Kann ich meiner eigenen Anzeigetafel trauen, und welche meiner Einschätzungen verdienen wirklich Konfidenz? Diesen Fragen ist es egal, ob das Thema Fußball, Fracht oder Rechnungen ist – und meiner Erfahrung nach wird das Upgrade auf ein schickeres Modell lange gejagt, bevor auch nur eine der beiden beantwortet ist. Wenn deine Arbeit auf Prognosen läuft und du dem Dashboard, das sie benotet, nie ganz getraut hast, kennst du das interessantere Problem zum Durchdenken bereits – und der ehrliche erste Schritt ist einfach, den nächsten Spieltag auf der öffentlichen Seite landen zu sehen, bevor du irgendetwas von dem, was ich gesagt habe, für bare Münze nimmst. Wenn du irgendwo hier deine eigene Welt statt eines Fußballplatzes gesehen hast, nun – du weißt, wo du mich findest.