cat artikel/ai-predictions-graded-matchday-2.mdx
Comunio World Cup 2026 · Teil 3Runde zwei der öffentlichen Bilanz: Die Prognosen wurden treffsicher — und schweigen darüber, wann sie danebenliegen
Runde zwei der öffentlichen Benotung meiner WM-Fantasy-KI: Die Ergebnis-Prognosen sprangen von 46 % auf 75 % — und dieselben Daten zeigen, dass sie kein Stück besser darin geworden ist zu erkennen, wann sie danebenliegt.
25. Juni 2026 · von Daniel Deusing · ~19 Min. Lesezeit #ai #agents #football
Im letzten Artikel habe ich gesagt, dass ich das nach der zweiten Spielrunde noch einmal mache — die Prognosen gegen das halten, was tatsächlich passiert ist, offen ausgesprochen, samt aller Fehlschüsse. Also hier ist Runde zwei. Sie ist irgendwo gelandet, was seltsamer ist als ein sauberer Sieg oder eine saubere Niederlage.
Eines möchte ich vorab klarstellen, weil man es leicht missverstehen kann: Ich trainiere keine KI darauf, Fußball vorherzusagen, und hier wird kein eigenes Modell gebaut. Ich nehme bestehende Modelle — dieselben, die jedes Unternehmen von der Stange bekommt — und gebe ihnen die Werkzeuge, den Kontext und die Anweisungen für eine bestimmte Aufgabe, und schärfe dann, wie sie das tun. Genau so sieht angewandte KI in der Praxis aus: Du baust nicht das Gehirn, du setzt ein gutes Gehirn auf dein Problem an.
Ich hatte nach der ersten Runde einen ganzen Stapel Dinge verändert, und die einzige Möglichkeit herauszufinden, ob sie wirklich funktionierten oder nur auf dem Papier gut klangen, war, noch eine Runde zu spielen und hinzuschauen. Hier ist also, was die Zahlen sagen — beide Hälften davon.
Die gute Nachricht: Den Sieger eines Spiels zu nennen, ist von 46 % richtig auf 75 % richtig gestiegen. Das ist die eine Zahl, die ich am meisten bewegen wollte, und sie hat sich stärker bewegt, als ich erwartet hatte.
Der Haken: Das System wurde deutlich besser darin, richtig zu liegen, ohne ein Stück besser darin zu werden zu erkennen, wann es danebenliegt. Diese Lücke — nicht der Fußball — ist das Nützlichste an diesem ganzen Text.
Lass mich dich durch beides führen, die Fehlschüsse offen auf dem Tisch.
Was tatsächlich besser wurde, und um wie viel
Zuerst die Zusammenfassung, falls du den letzten Artikel nicht gelesen hast — denn der ganze Sinn ist, dass du mich überprüfen kannst.
Ich bin in einem Fantasy-Spiel, in dem ein Team aus KI-Agenten die tägliche Hausaufgabe erledigt: An jedem Spieltag sagen sie voraus, wer in jedem Spiel beginnt und wie jedes Spiel ausgeht, und dann benotet die Realität sie. In Runde eins war das Urteil ein sauberer Riss durch die Mitte. Das System war bereits gut darin, wer in der Startelf steht (der wissbare Teil) zu nennen, und schlicht schlecht darin, das Ergebnis (der chaotische Teil) zu nennen. Es hatte den Sieger nur in 46 % der Fälle richtig — kaum besser als das Werfen einer dreiseitigen Münze zwischen Sieg, Unentschieden und Niederlage.
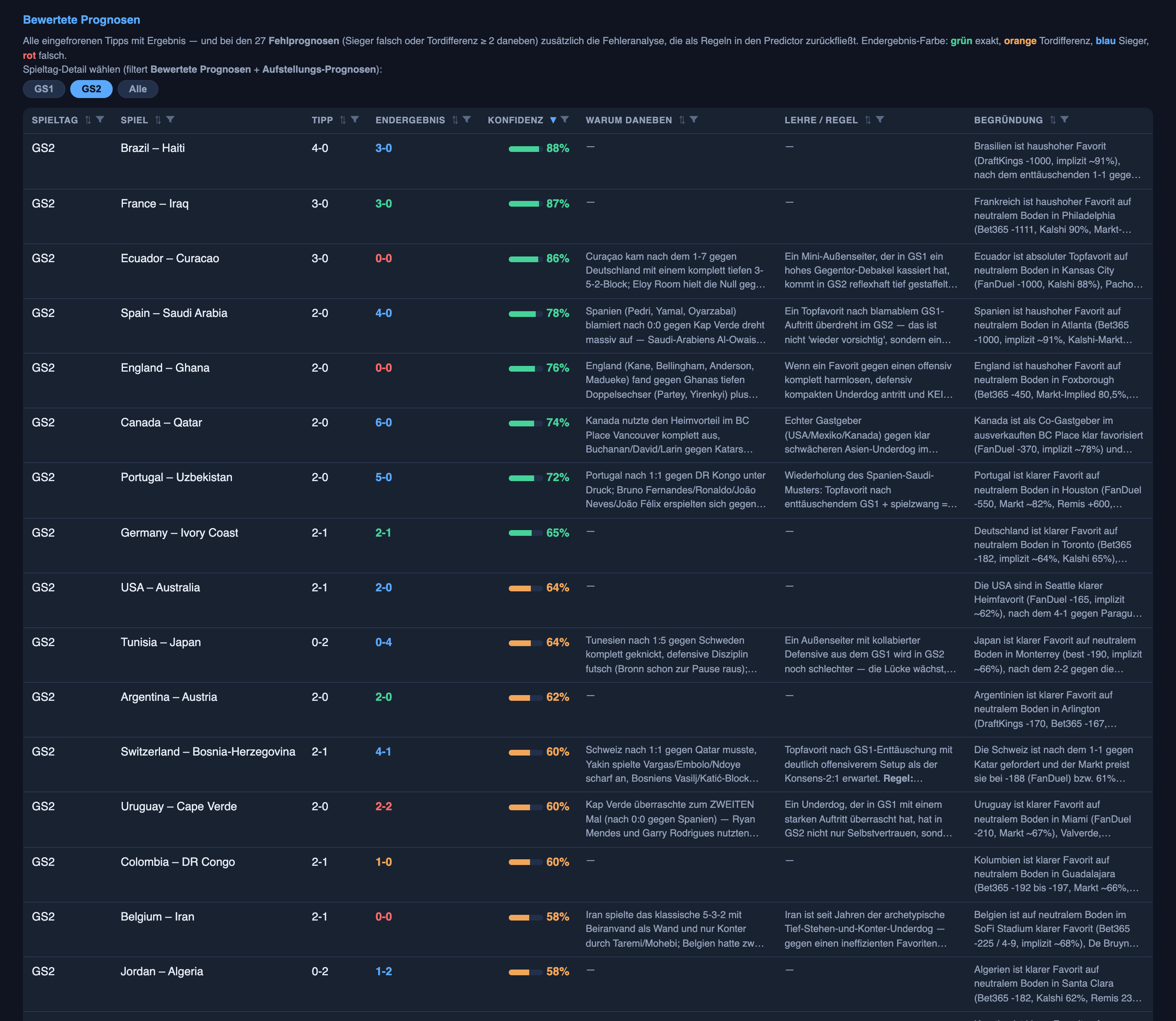
Runde zwei, gleiche Wertung, keine Ausreden:
- Sieger richtig: 11 von 24 Spielen in Runde eins (46 %) → 18 von 24 in Runde zwei (75 %).
- Tordifferenz richtig: 2 von 24 → 5 von 24 — der richtige Abstand, selbst wenn das exakte Ergebnis daneben lag (getippt 2–0, am Ende 3–1).
- Exaktes Ergebnis richtig: 2 von 24 (8 %) → 3 von 24 (13 %).
- Wie weit die Tore im Schnitt daneben lagen: im Grunde unverändert (etwa ein Tor pro Seite, in beiden Runden).
Das System wurde also deutlich besser darin, wer gewinnt zu treffen, besser beim Abstand, ein bisschen besser beim exakten Ergebnis, und kein Stück besser bei der reinen Anzahl an Toren, die es erwartete — was genau das ist, was du erwarten würdest, wenn es etwas Echtes über Fußball gelernt hätte, statt Glück zu haben. Den Sieger zu treffen, ist eine Frage mit Signal darin. Die genaue Anzahl an Toren in einem einzelnen torarmen Spiel festzunageln, ist überwiegend Glück, und Glück lernt nicht.
Warum es besser wurde — der Teil, der aufhört, vom Fußball zu handeln
Hier ist der Mechanismus, denn hier hört es auf, eine Sportgeschichte zu sein, und beginnt eine Geschichte über jedes System zu sein, das über die Zeit klüger werden soll.
Nach Runde eins ging ein Evaluator-Agent durch jeden Fehlschuss und schrieb auf, was er falsch gemacht hatte — nicht als Datenhaufen, sondern als kurze Liste in einfacher Sprache, jeder Punkt mit Beleg. Vor Runde zwei las der Agent, der die Prognosen erstellt, diese Liste und passte sich an. Das ist die gesamte Schleife.
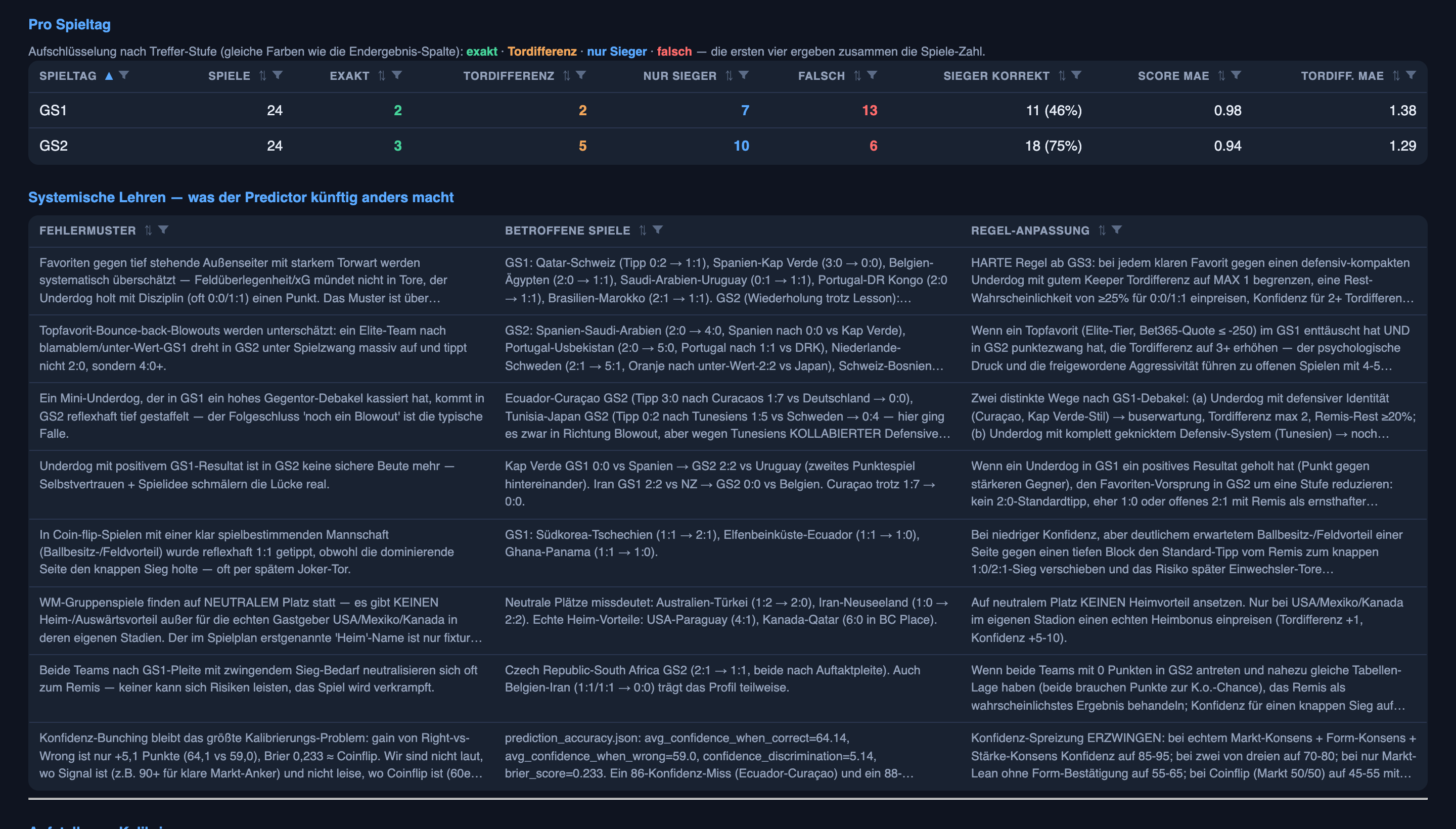
Zwei der Lektionen, die es nach Runde eins aufgeschrieben hat — und die ehrliche Aufteilung, was jede davon bewirkt hat:
- „Bei einem Turnier auf neutralem Boden gibt es keinen Heimvorteil.” Eine dumme Annahme, übernommen aus dem normalen Ligafußball, hatte dem zuerst genannten Team still und leise einen Vorteil verschafft. Gelöscht. Kleine Korrektur, echte Wirkung.
- „Verwechsle geringe Zuversicht nicht mit wenigen Toren — hör auf, die Kantersiege abzusichern.” Diese hier hat es aufgeschrieben und dann nicht befolgt. In Runde eins tippte es höfliche 2–0 in Spielen, die zu Abreibungen wurden (Deutschland gewann 7–1 nach einem 3–0-Tipp). In Runde zwei machte es dasselbe — Spanien, Portugal und die Niederlande alle vorsichtig auf 2–0 oder 2–1 getippt, dann aber 4–0, 5–0 und 5–1 gewonnen. Es traf die Sieger; es unterschätzt das Ausmaß immer noch heftig. Eine Lektion in den Büchern ist noch keine Lektion in den Knochen — und die Abstände sind die Stelle, an der dieses System am schwächsten bleibt.
Du kannst jede einzelne dieser Lektionen in einfacher Sprache nachlesen. Das ist das Feature, nicht eine nette Beigabe. Ein System, dessen Lernen du einsehen und überstimmen kannst, ist eines, das du in einem Unternehmen laufen lassen kannst; eine Blackbox, die „einfach besser wird”, ist eine, die du nie an deinem Prüfer vorbeibekommst. Und es schneidet in beide Richtungen — ein Evaluator kann eine Lektion schreiben, die weise klingt und tatsächlich falsch ist, was genau der Grund ist, warum ein Mensch das Notizbuch liest, bevor es die nächste Runde speist.
Der Haken: Richtig zu liegen ist nicht dasselbe wie seine Chancen zu kennen
Jetzt der Teil, den ich nicht erwartet hatte, und der Grund, warum ich keinen Champagner aufmache.
Eine Prognose kommt mit einer Zuversichtszahl — „Ich bin mir hier zu 70 % sicher.” Der ehrliche Test dieser Zahl ist nicht, ob die Aussage richtig war. Es ist, ob die Zuversicht der Realität folgt.
Folgendes ist mit dieser zweiten Tugend zwischen den beiden Runden passiert:
- Runde eins: Das System war im Schnitt etwa 65 % zuversichtlich bei den Spielen, die es richtig hatte, und 57 % bei denen, die es falsch hatte. Eine Lücke von acht Punkten — bescheiden, aber seine Zuversicht lehnte sich in die richtige Richtung.
- Runde zwei: etwa 64 % zuversichtlich, wenn richtig, und 64 % zuversichtlich, wenn falsch. Die Lücke brach auf ungefähr null zusammen.
Ich habe diese Aufteilungen pro Runde selbst aus den rohen Prognose-und-Ergebnis-Protokollen herausgezogen — die zusammengefasste Genauigkeitsseite mischt beide Runden zu einer Zahl, das ist also ich, der die Rechnung zeigt, und nicht ich, der dich bittet, es mir aufs Wort zu glauben.
Lies das noch einmal. Das System hat seine Trefferquote nahezu verdoppelt — und seine Zuversicht hörte vollständig auf, seine Treffer von seinen Fehlschüssen zu unterscheiden. Es wurde besser bei der Antwort und schlechter darin zu wissen, wie sicher es sein sollte.
Wie können beide wahr sein? Wegen der Frage, welche Spiele es immer noch falsch hatte. Die meisten Fehlschüsse der zweiten Runde reimten sich: ein klarer Favorit, ein Außenseiter, der seinen Strafraum vor einem heißen Torwart vollpackt, und ein Ergebnis, das nicht brechen wollte. Drei endeten 0–0 — Ecuador, getippt, Curaçao 3–0 zu schlagen; England, getippt, Ghana 2–0 zu schlagen; Belgien gegen Iran — und ein viertes, die Tschechen, wurden auf ein 1–1 gehalten. (Die anderen beiden brachen anders: Uruguay wurde auf ein 2–2 zurückgeholt, und die Türkei verlor klar gegen Paraguay.) Das System war zuversichtlich bei diesen Favorit-gehalten-Spielen — auf dem Papier durchaus berechtigt — und jedes Mal falsch. Zuversichtlich-und-falsch bei einem sich wiederholenden Muster ist die schlimmste Fehlerart, die ein Prognostiker haben kann, weil es sich nicht wie ein Raten anfühlt. Es fühlt sich wie Wissen an.
Dieses Muster ist daher jetzt eine harte Regel für Runde drei, kein sanfter Schubs: Gegen einen tief verteidigenden Außenseiter mit einem guten Keeper deckle den Abstand und kalkuliere eine echte Chance auf ein Unentschieden ein — besonders, wenn dieser Außenseiter bereits einem Stärkeren einen Punkt abgeknöpft hat. Ob die Regel funktioniert, ist, wieder einmal, etwas, das du in der nächsten Runde überprüfen kannst, statt es mir aufs Wort zu glauben.
Die Aufstellungs-Seite: schon gut, und sie blieb gut
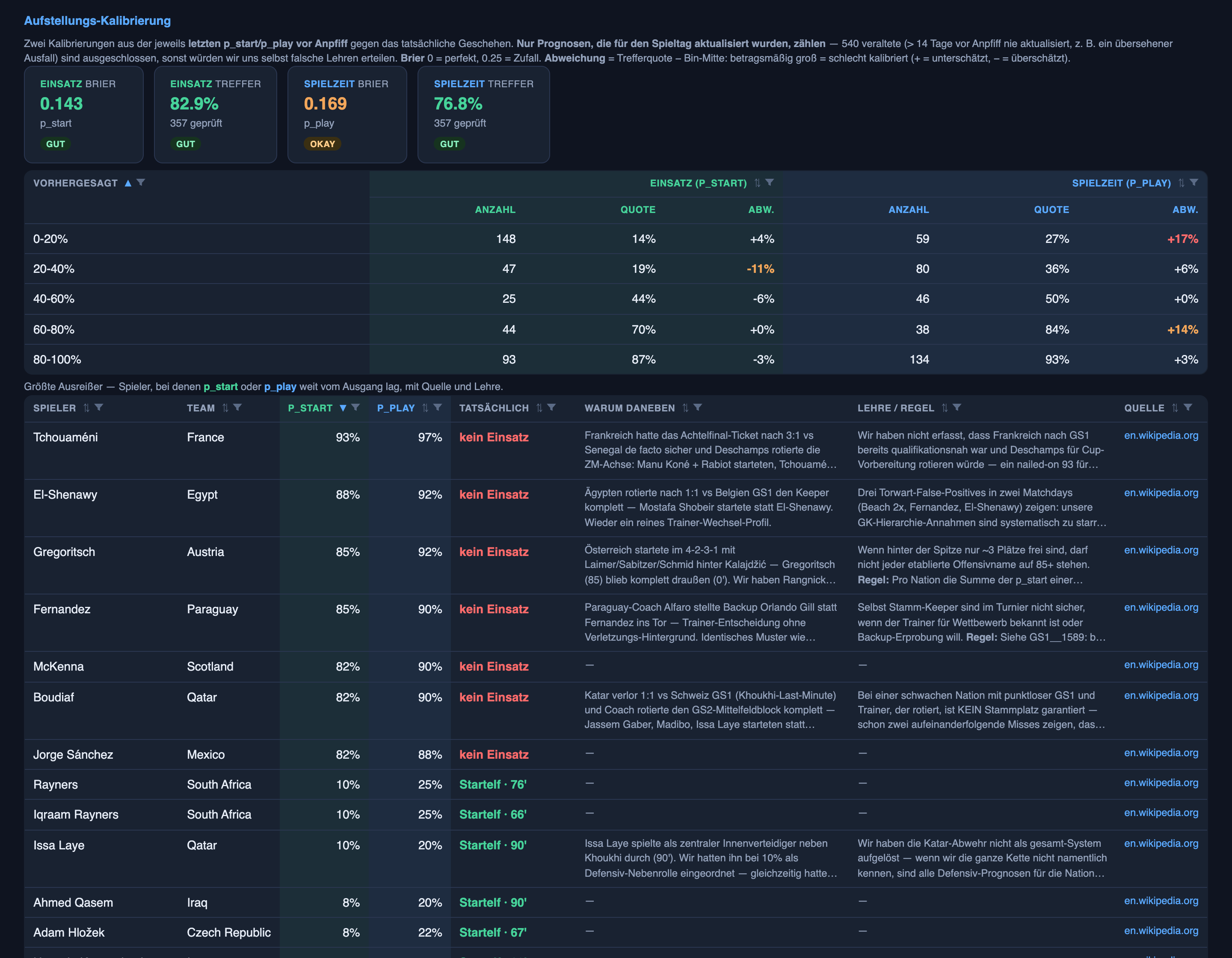
Die andere Hälfte des Systems — vorherzusagen, wer tatsächlich beginnt — war im letzten Artikel die starke Hälfte, und das ehrliche Update ist undramatisch: Sie blieb stark. Über 357 Startelf-Aussagen in beiden Runden hinweg (die veralteten herausgeworfen) lag sie in etwa 83 % der Fälle richtig, von Runde zu Runde im Grunde gleichbleibend.
Was sich tatsächlich verbessert hat, ist die Form seiner Zuversicht. Im letzten Artikel habe ich angemerkt, dass das System, wenn es „ziemlich wahrscheinlich” sagte (das 60–80 %-Band), etwa acht Punkte zu heiß lief. Dieses Band ist jetzt nahezu perfekt kalibriert — Spieler, die es in diesen Bereich einordnet, beginnen fast genau so oft, wie es sagt. Die hartnäckige Schwachstelle ist immer noch die schlammige Mitte, das 20–40 %-Band: immer noch überzuversichtlich — etwa elf Punkte zu heiß, herunter von rund achtzehn in Runde eins. Echter Fortschritt, noch keine Lösung.
Aber Runde zwei brachte auch zwei Aufstellungs-Lektionen zum Vorschein, die es wert sind, benannt zu werden, denn jede ist eine Falle, die nichts mit Fußball zu tun hat:
- Das System vertraute einem berühmten Namen mehr als dem aktuellen Mannschaftsbogen — und schrieb sich dann genau die falsche Lektion darüber auf. Der Torwart ist die beständigste Position auf dem Platz, und doch waren die zuversichtlichen Torwart-Aussagen unter den schlimmsten Fehlschüssen: Australien spielte Beach, einen Keeper, den wir mit 2 % abgeschrieben hatten, über die vollen 180 Minuten, während der erfahrene Name, den wir mit 90 % eingeplant hatten, nie aufs Feld kam. Der systemeigene Evaluator legte das unter einer schicken Regel ab — „Torwart-Rotation ist bei einem Turnier die Norm” — die eine Handvoll Fehlschüsse zu einem falschen Muster überinterpretiert; Keeper rotieren kaum. Der eigentliche Fehlschuss war ein bekannterer Name, der für den aktuellen Stammtorwart einsprang, und die eigentliche Korrektur ist langweilig: bestätige, wer tatsächlich in der Elf steht, vertraue nicht dem Trikot. Ich habe die schlechte Lektion gelöscht, bevor sie die nächste Runde speiste — was der ganze Grund ist, warum ein Mensch das Notizbuch immer noch liest.
- Die peinlichste: ein Prozessfehler, wiederholt. Drei Stammspieler, die wir in Runde eins zu niedrig angesetzt hatten, blieben in Runde zwei zu niedrig angesetzt, weil ihre Prognosen nie aufgefrischt wurden — genau der Fehler, dessen Behebung ich im letzten Artikel beschrieben hatte, angewandt auf die falschen Spieler. Die Lektion war richtig; die Disziplin, sie auf jeden betroffenen Namen anzuwenden, war noch nicht da. Die Korrektur in dieser Runde ist also mechanisch, nicht clever: Vor jedem Spieltag erzwinge eine Auffrischung bei jedem Stammspieler, der noch auf einer veralteten niedrigen Zahl sitzt. Die unglamouröse Hälfte der Arbeit ist, wieder einmal, dort, wo sich die echten Fehler verstecken.
Die Tabelle, ehrlich
Du willst wissen, ob irgendwas davon gewinnt. Ja — ich bin Erster, mit 145 Punkten, neun vor dem Zweiten, und insgesamt das wertvollste Team der Liga, Kader plus Bargeld, um etwa fünf Millionen.
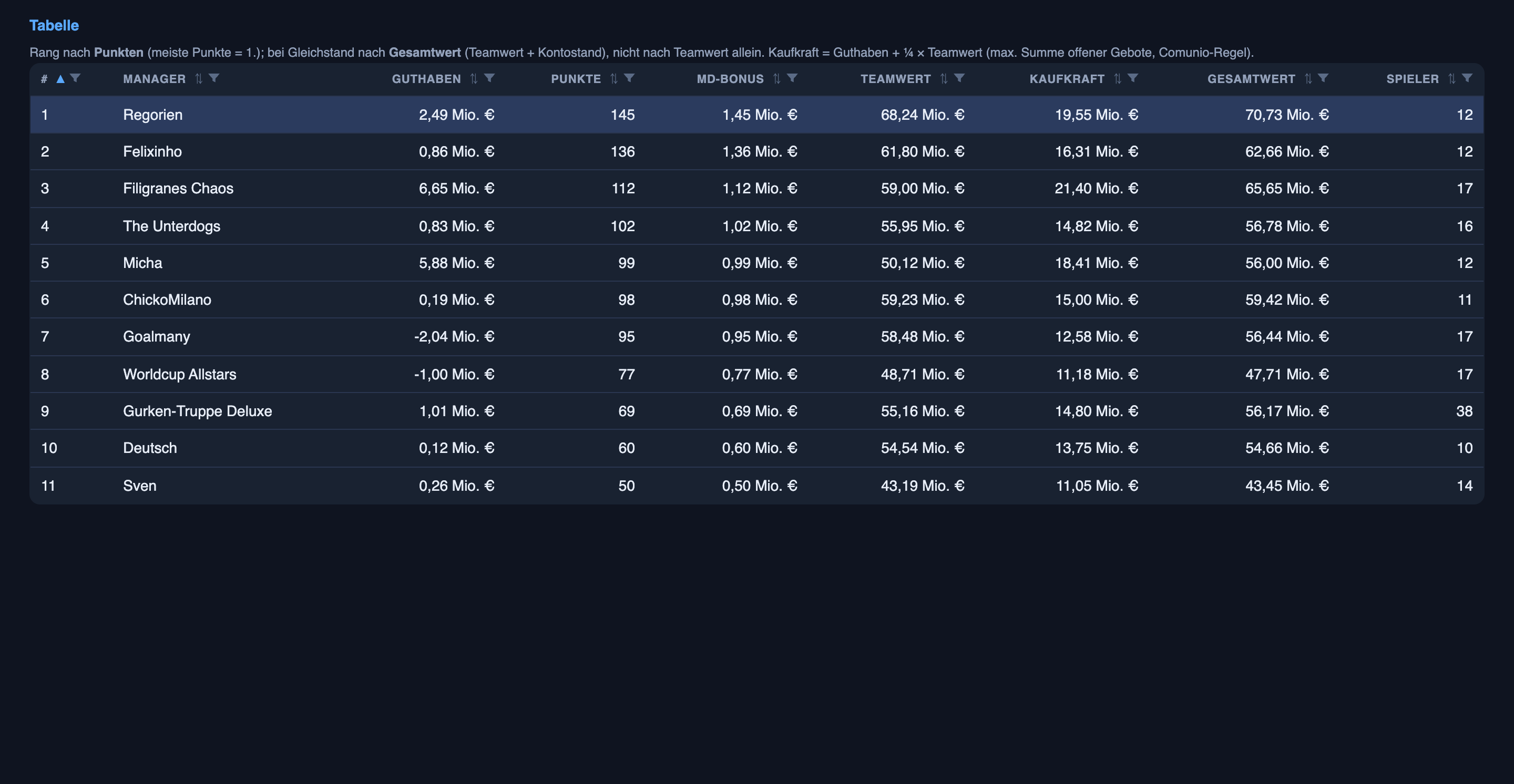
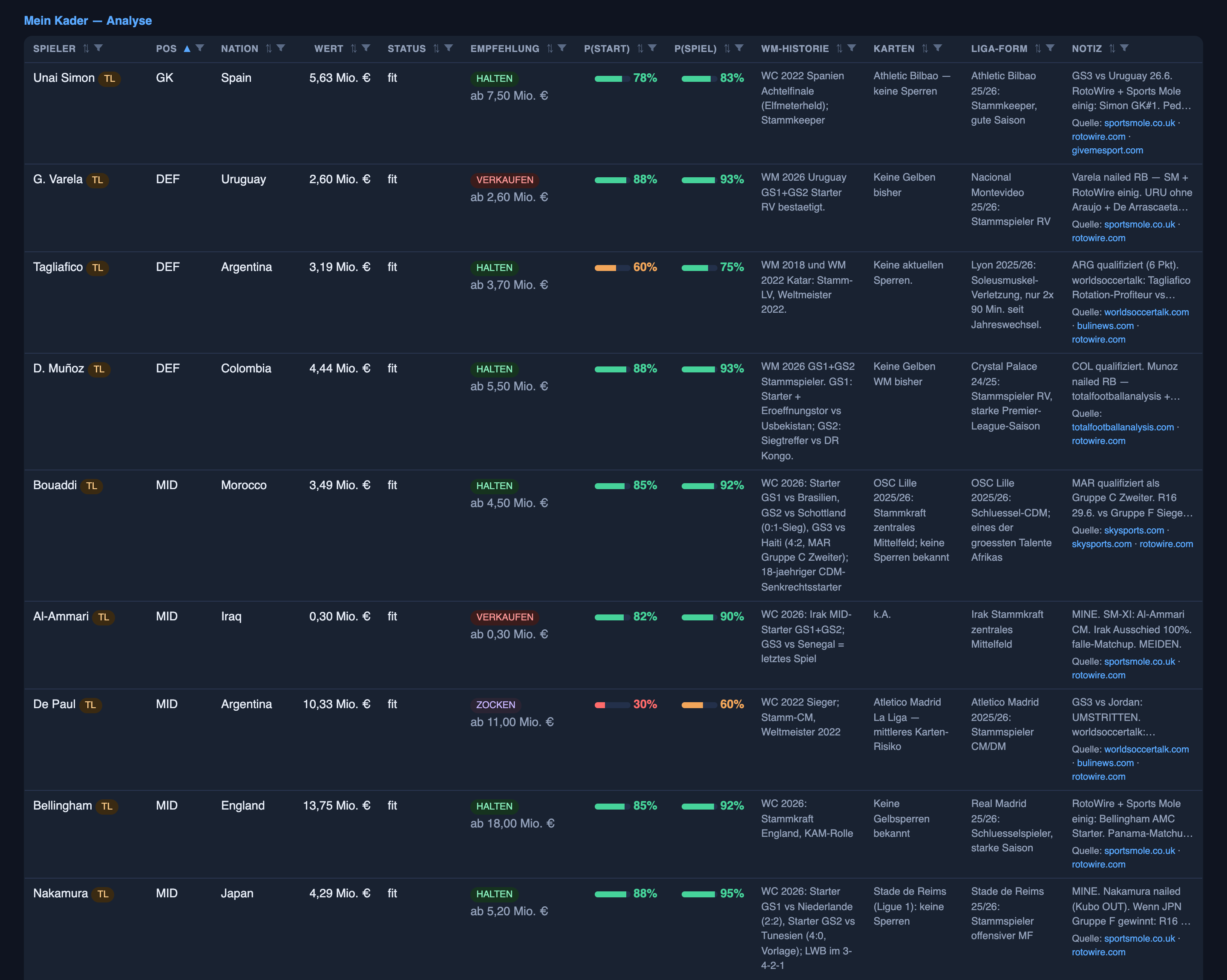
Hier ist der ehrliche Teil: Die Führung kommt nicht von den Ergebnis-Prognosen. Die auffälligen Wer-gewinnt-und-mit-welchem-Abstand-Aussagen sind ein nützliches Werkzeug, das schärfer wird, aber sie sind nicht das, was die Liga gewinnt. Der Vorteil ist die leisere Hälfte desselben Systems. Die KI recherchiert jeden Spieler und sagt voraus, wer tatsächlich beginnt — die p_start- und p_play-Zahlen von vorhin — und dieses Wissen wird auf dem Transfermarkt zu Geld: Ich kaufe billige Spieler, die still und leise sichere Stammspieler sind, bevor ihr Preis aufholt, beurteile, ob ein zweifelhafter Name das Risiko wert ist, und biete gezielt, statt zu überzahlen. Füge einen Bonus pro Punkt hinzu, der sich aufsummiert — mehr Punkte, mehr Bargeld, bessere Spieler, mehr Punkte — und das ist der eigentliche Motor. Die KI ist also ein großer Grund, warum ich oben stehe; nur die Wer-spielt-Recherche, nicht die Wer-gewinnt-Prognosen. Die Ergebnis-Aussagen sind die öffentliche Bilanz; die Aufstellungs-Aussagen sind der Vorteil.
Was die Menschen tun — und was es dir über jede Auktion verrät
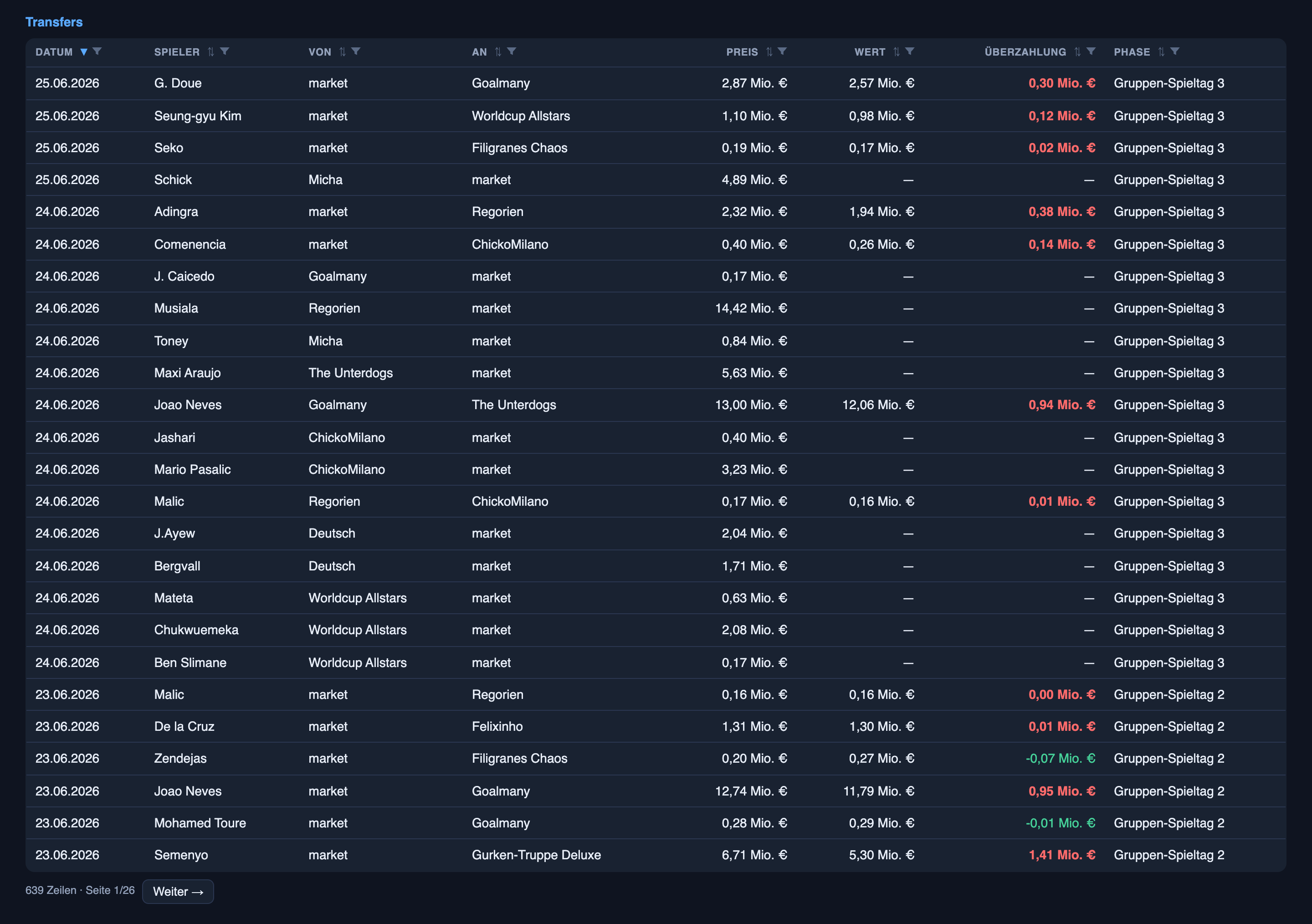
Es gibt einen zweiten Datensatz, der sich in dieser Liga versteckt und nichts mit Prognosen zu tun hat und alles damit, wie sich Menschen verhalten, wenn sie im Dunkeln gegeneinander bieten. Spieler wechseln in einer Blindauktion den Besitzer — verdeckte Gebote, niemand sieht das der anderen, die höchste Zahl gewinnt — und das Hauptbuch hält jetzt 639 dieser Transaktionen. Die Muster darin sind das Geschäftsrelevanteste, das ich habe.
Menschen überzahlen, fast immer. Von den Käufen mit einem Marktwert-Bezug gingen 85 % über den gelisteten Wert — das mittlere Gebot landete etwa 21 % über dem Marktpreis des Spielers, der Durchschnitt etwa 39 % darüber, und ein verzweifeltes Gebot kam bei fast dem Fünffachen des gelisteten Werts an. Überzahlen ist hier nicht die Ausnahme; es ist die Regel. Der Grund ist strukturell und es lohnt sich, ihn zu verstehen: In einer Auktion mit verdeckten Geboten zahlst du nicht, was die Sache wert ist, du zahlst, was du befürchtest, dass die nächste Person bietet — und der Besitzer verkauft ohnehin nicht zum Nennwert. Der „Marktwert” ist ein Bezugspunkt, kein Preis.
Der Rausch ballt sich am Anfang. Die Aktivität war am stärksten bevor das Turnier losging — Kaderbau-Saison, etwa neunzehn Wechsel pro Tag — und kühlte dann auf rund vierzehn pro Tag ab, sobald echte Spiele begannen und die meisten Kader standen. Auch das Überbieten kühlte ab: Der typische Aufschlag schrumpfte, sobald die Partien im Gange waren und die Manager weniger Grund hatten nachzujagen. Menschen sind am kühnsten, wenn das Feld weit offen ist und der Einsatz noch abstrakt, und disziplinierter, sobald die Spiele — und die Konsequenzen — echt sind.
Mit den herannahenden K.-o.-Runden liegen bereits sieben offene Gebote auf meine Spieler im Posteingang — der Markt wacht wieder auf.
Zwei Prognosen für das, was kommt — jetzt laut ausgesprochen, später benotet
Eine Prognose, die du nach der Tatsache machst, ist wertlos. Hier sind also zwei, die ich jetzt ausspreche, vor Runde drei und den K.-o.-Runden — um genau wie alles andere öffentlich benotet zu werden.
Prognose eins — Runde drei wird jeden bestrafen, der dem Namen eines Stars vertraut. Sieben Teams haben bereits beide Spiele gewonnen — Deutschland, Frankreich, Argentinien, Mexiko, die USA, Kolumbien und Norwegen — sie gehen also mit einem Bein in der nächsten Runde und wenig zu jagen ins letzte Gruppenspiel. Ein Trainer in dieser Lage hat allen Grund, wichtige Beine für die Runden zu schonen, die zählen. Meine Prognose für Runde drei: eine Welle überraschender Rotationen bei den Spitzenreitern, und die Aufgabe des Aufstellungs-Modells ist es, sie früh zu erwischen — der p_start eines Stars sollte fallen, nicht weil er verletzt ist, sondern weil sein Trainer ihn schont. Das System behandelt ein Team, das wenig zu spielen hat, jetzt als ausdrückliches Rotations-Signal. Wir werden in der nächsten Runde sehen, ob das reicht.
Prognose zwei — die K.-o.-Runden werden die gesamte Transferliste neu bepreisen. Nach Runde drei wird das Format brutal und einfach: Das Feld halbiert sich jede Runde — 32 Teams, dann 16, dann 8, dann 4, dann 2 — und ab dem Achtelfinale zählt jeder Punkt, den ein Spieler holt, doppelt.
Hier ist also die Prognose: Wenn die Gruppenphase endet und ein Drittel der Teams nach Hause fährt, erwarte einen zweiseitigen Ansturm auf die Transferliste. Einen Ausverkauf von Spielern ausgeschiedener oder verblassender Nationen — tote Vermögenswerte, die niemand halten will — und, zur gleichen Zeit, Bieterkriege um die gesetzten Startspieler der echten Anwärter, wobei das Überbieten, das ich oben beschrieben habe, an der Spitze schlimmer wird, weil ein doppelt punktender K.-o.-Startspieler es wert ist, über jeden vernünftigen Preis hinaus gejagt zu werden. Die Manager, die früh handeln — bevor der Turnierbaum offensichtlich ist — werden weniger zahlen als die, die auf Gewissheit warten. Ich werde berichten, ob es tatsächlich so gelaufen ist.
Streich den Fußball heraus
Lies diesen ganzen Text noch einmal und streich das Wort „Fußball”.
Ein Prognosesystem wurde umgebaut und es wurde messbar genauer — und genau dieselben Daten zeigten, dass es aufgehört hatte, dir sagen zu können, welcher seiner Aussagen du vertrauen sollst. Diese zweite Tatsache ist die, die dir Sorgen machen sollte, denn ein Modell, das bei einem sich wiederholenden Muster zuversichtlich falsch liegt, ist gefährlicher als eines, das ehrlich unsicher ist. Wenn dir jemand ein Modell verkauft, das „seine Genauigkeit auf 75 % verbessert hat”, ist die nächste Frage nicht „wie hoch kann es gehen” — sondern „und weiß es, wann es kurz davor ist, danebenzuliegen?” Verfolge beide Zahlen, oder du wirst zuversichtlich und falsch zugleich sein.
Der Rest lässt sich genauso sauber übertragen. Das Lernen, das zählte, war kein größeres Modell; es war ein lesbares Notizbuch der Fehler, das ein Mensch prüfen und überstimmen kann — so übersteht eine KI-Verbesserung den Kontakt mit einem Unternehmen. Die Fehler, die am härtesten zubissen, waren nicht die KI, die clever oder dumm war; es waren langweilige Prozessfehler, wie eine veraltete Zahl, die nie aufgefrischt wurde. Und die Daten über menschliches Verhalten — Überzahlen als Standard, am kühnsten, wenn der Preis noch abstrakt ist — sind die Form jedes Wettbewerbsgebots, das dein Unternehmen je gemacht hat.
Bedarfsprognose, Abwanderungserkennung, Lieferanten-Risiko-Überwachung, Preisgestaltung unter Termindruck — gleiche Maschinerie, gleiche Fallen, dieselben zwei Fragen, die mehr wert sind als jedes Modell-Upgrade: Kann ich meiner eigenen Anzeigetafel vertrauen, und verdienen meine zuversichtlichen Aussagen die Zuversicht tatsächlich? Die Fußballer machen die Anzeigetafel bloß öffentlich und den Einsatz niedrig genug, um dir das Ganze zu zeigen, samt aller Fehlschüsse.
Ein letzter Gedanke, bevor ich dich gehen lasse. Die nützlichste Zahl dieser Runde waren nicht die 75 %. Es war die Zuversichtslücke, die auf null schrumpfte — das System, das mir leise mitteilte, es habe gelernt zu gewinnen, ohne gelernt zu haben zu zweifeln. Das weiß ich lieber, als es nicht zu wissen. Wenn deine Arbeit auf Prognosen läuft und du nie „wie oft liegt es richtig” von „weiß es, wann es das nicht tut” getrennt hast, ist das das interessantere Problem auf deinem Schreibtisch — und du kannst zusehen, wie Runde drei auf der öffentlichen Seite landet, bevor du auch nur ein Wort hiervon aufs Wort glaubst. Wenn du irgendwo hierin deine eigene Welt statt eines Fußballplatzes gesehen hast, weißt du, wo du mich findest.